
Una vez iniciado el servidor ambari podemos entrar a la UI web que es la herramienta que utilizaremos para definir y realizar el despliegue del clúster. Esta aplicación web está disponible en el puerto 8080 del nodo administrador: http://hadoop-admin1.tartangalh.eus:8080/
Una vez dentro, iniciamos un proceso de configuración paso a paso mediante asistente del despliegue a realizar del clúster. A continuación detallamos los diferentes pasos de este asistente.
-
- Lanzamos el asistente de instalación del clúster:
- Establecemos el nombre del clúster:
- En el siguiente paso vamos a subir el archivo de definición del stack (VDF) de Hadoop elegido:

Dicho archivo refiere los servicios disponibles en la pila de Hadoop a desplegar, así como la URL del repositorio a utilizar para los sistemas operativos elegidos. Tiene el siguiente contenido:
<?xml version="1.0"?>
<repository-version xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="version_definition.xsd">
<release>
<type> STANDARD </type>
<stack-id> BGTP-1.0 </stack-id>
<version> 1.0 </version>
<build> 1 </build>
<release-notes> https://bigtop.apache.org/release-notes.html </release-notes>
<display> BGTP-3.1.1 </display>
</release>
<manifest>
<service id="AMBARI-METRICS" name="AMBARI-METRICS" version="Bigtop+3.2"/>
<service id="FLINK-321" name="FLINK" version="Bigtop+3.2"/>
<service id="HBASE-321" name="HBASE" version="Bigtop+3.2"/>
<service id="HDFS-321" name="HDFS" version="Bigtop+3.2"/>
<service id="HIVE-321" name="HIVE" version="Bigtop+3.2"/>
<service id="KAFKA-321" name="KAFKA" version="Bigtop+3.2"/>
<service id="SOLR-321" name="SOLR" version="Bigtop+3.2"/>
<service id="SPARK-321" name="SPARK" version="Bigtop+3.2"/>
<service id="TEZ-321" name="TEZ" version="Bigtop+3.2"/>
<service id="YARN-321" name="YARN" version="Bigtop+3.2"/>
<service id="ZEPPELIN-321" name="ZEPPELIN" version="Bigtop+3.2"/>
<service id="ZOOKEEPER-321" name="ZOOKEEPER" version="Bigtop+3.2"/>
</manifest>
<available-services/>
<repository-info>
<os family="ubuntu18">
<repo>
<baseurl> http://repos.bigtop.apache.org/releases/3.1.1/ubuntu/18.04/$(ARCH) </baseurl>
<repoid> BGTP-3.1.1 </repoid>
<reponame> BGTP </reponame>
</repo>
</os>
</repository-info>
</repository-version>
Una vez cargado el archivo VDF, revisamos la información en la web UI y finalizamos la selección de la versión (Nótese que marcamos la opción para evitar la validación de la URL del repositorio):
- En el siguiente paso, “Install Options”, introducimos los nombres DNS de los nodos que van a componer el clúster, así como el valor de la clave privada SSH para el acceso remoto a dichos nodos (recordar finalizar el contenido del campo para la clave en la siguiente línea a la última con contenido de la clave):

- Al pulsar “Register and Confirm” , el servidor Ambari contactará con cada uno de los host y realizará una serie de acciones para comprobar que se puede comunicar correctamente con dichos hosts y que podrá ejecutar las tareas de instalación y configuración durante el despliegue. En este paso, se transfiere a los hosts el agente ambari y se realiza alguna configuración sobre los sistemas de dichos hosts. Si se produce algún error, se nos mostrará en la propia web UI y habremos de corregirlo antes de que el asistente nos permita avanzar. Es decir, para continuar, en este paso todos los hosts tienen que aparecer con status “Success”.

En esta misma página podemos visualizar un detalle del chequeo que se ha realizado en cada host, con un desglose de problemas detectados: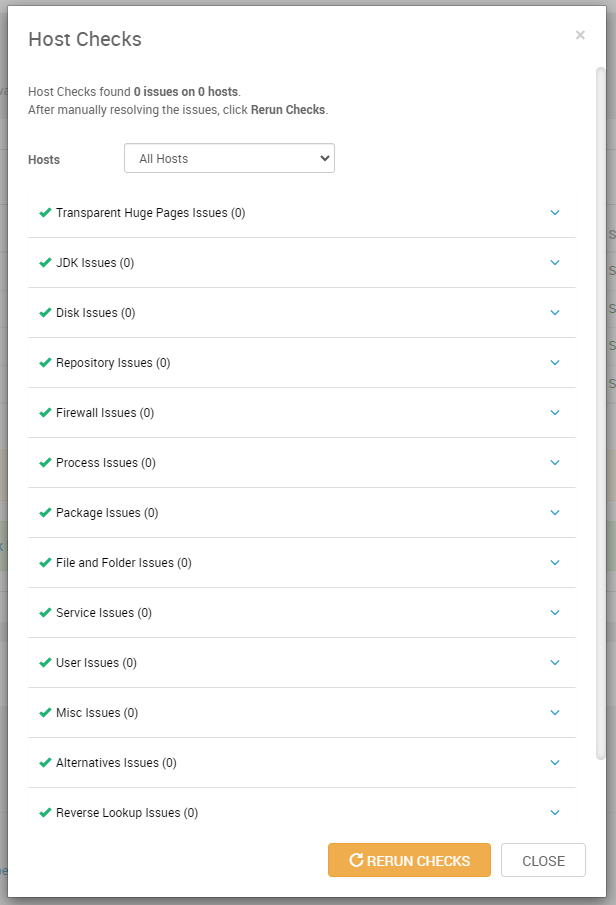
- En el siguiente paso, “Choose Services”, vemos los servicios que se van a desplegar en el clúster, pudiendo elegir una selección de ellos. En nuestro caso vamos a instalar todos los definidos en la versión seleccionada anteriormente:

- Seguidamente, asignamos todos los servicios de tipo “Master ” al que será nodo máster de nuestro clúster:
hadoop-master1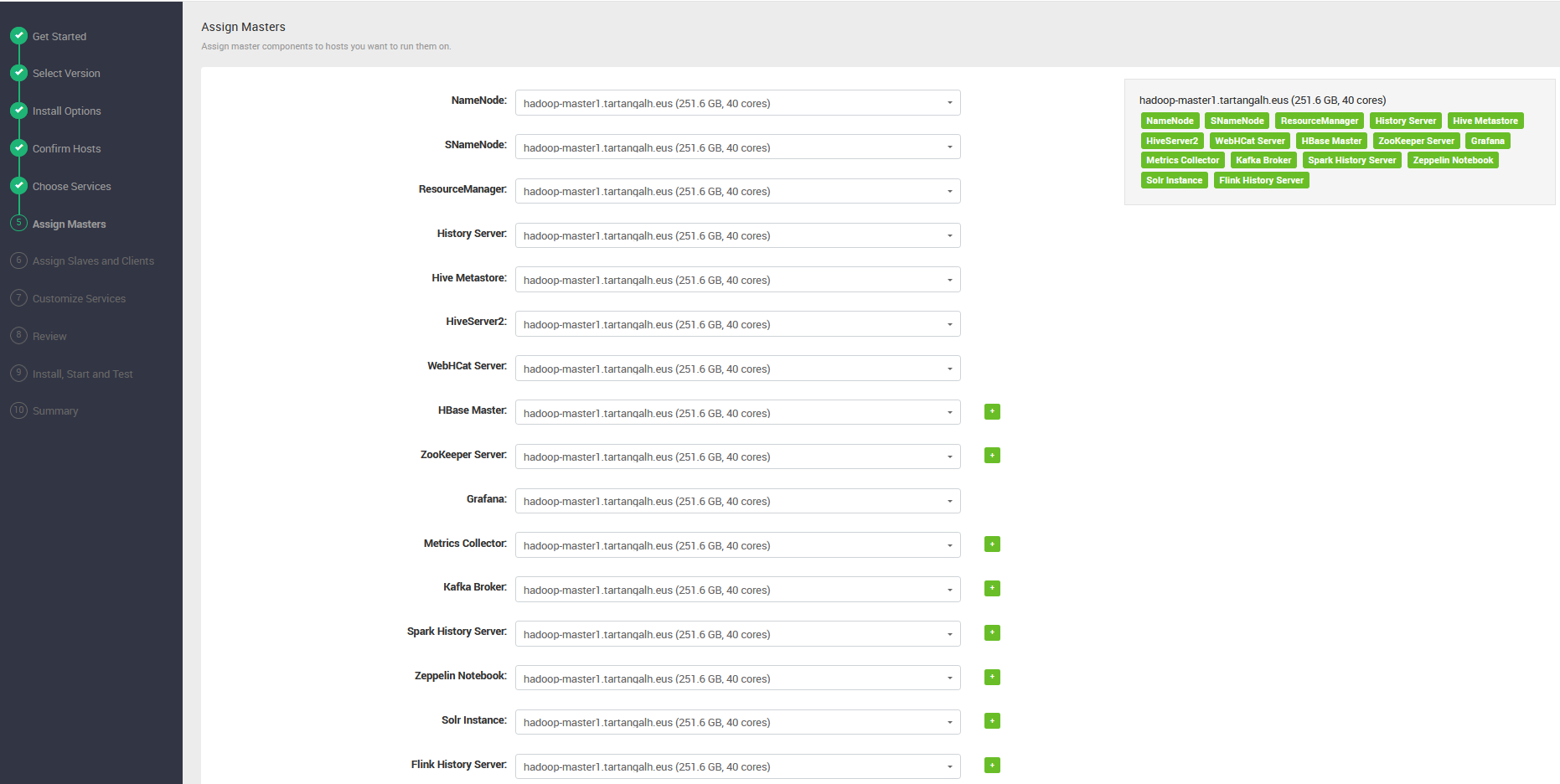
- A continuación, asignamos los servicios de tipo Client o Slave a los nodos trabajadores:
hadoop-worker1, hadoop-worker2 y hadoop-worker3
- El siguiente paso es el más laborioso del proceso de configuración pre-despliegue ya que mediante una serie de páginas hemos de personalizar los parámetros que nos interesen de los diferentes servicios. Téngase en cuenta que la inmensa mayoría de parámetros de los servicios se pueden reconfigurar una vez el clúster esté desplegado, lo que forma parte del mantenimiento del clúster. No obstante, hay parámetros fundamentales, como los puntos de montaje de los sistemas de archivo o los parámetros de las bases de datos de soporte, por ejemplo, que han de ser ajustados en este momento para un exitoso despliegue del clúster. Los pasos de esta personalización son:
- Credenciales: establecemos las credenciales para usuarios de Grafana y Hive:
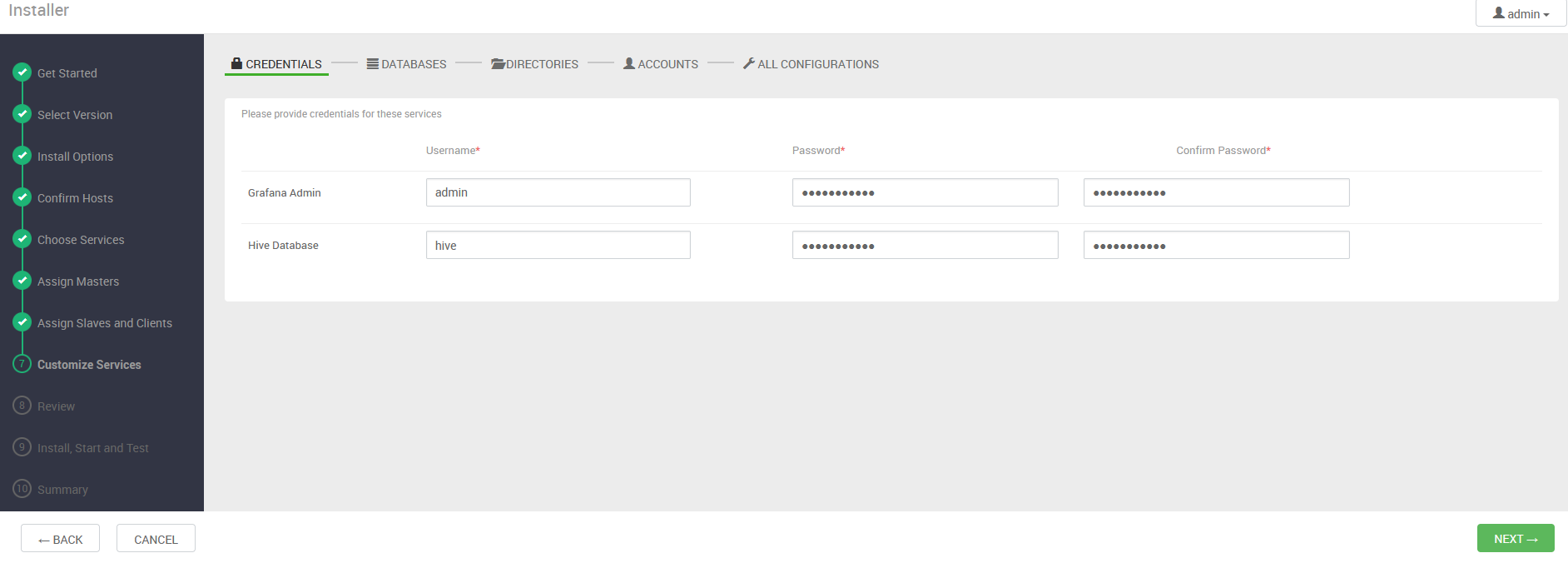
- Bases de Datos: definimos que servidor de base de datos , base de datos y usuario vamos a utilizar para Hive. Nótese que si no está instalado y configurado el sistema gestor de base de datos en el nodo máster, hemos de instalarlo y configurarlo previamente (vea el Procedimiento de instalación y configuración de PostgreSQL en nodo máster)

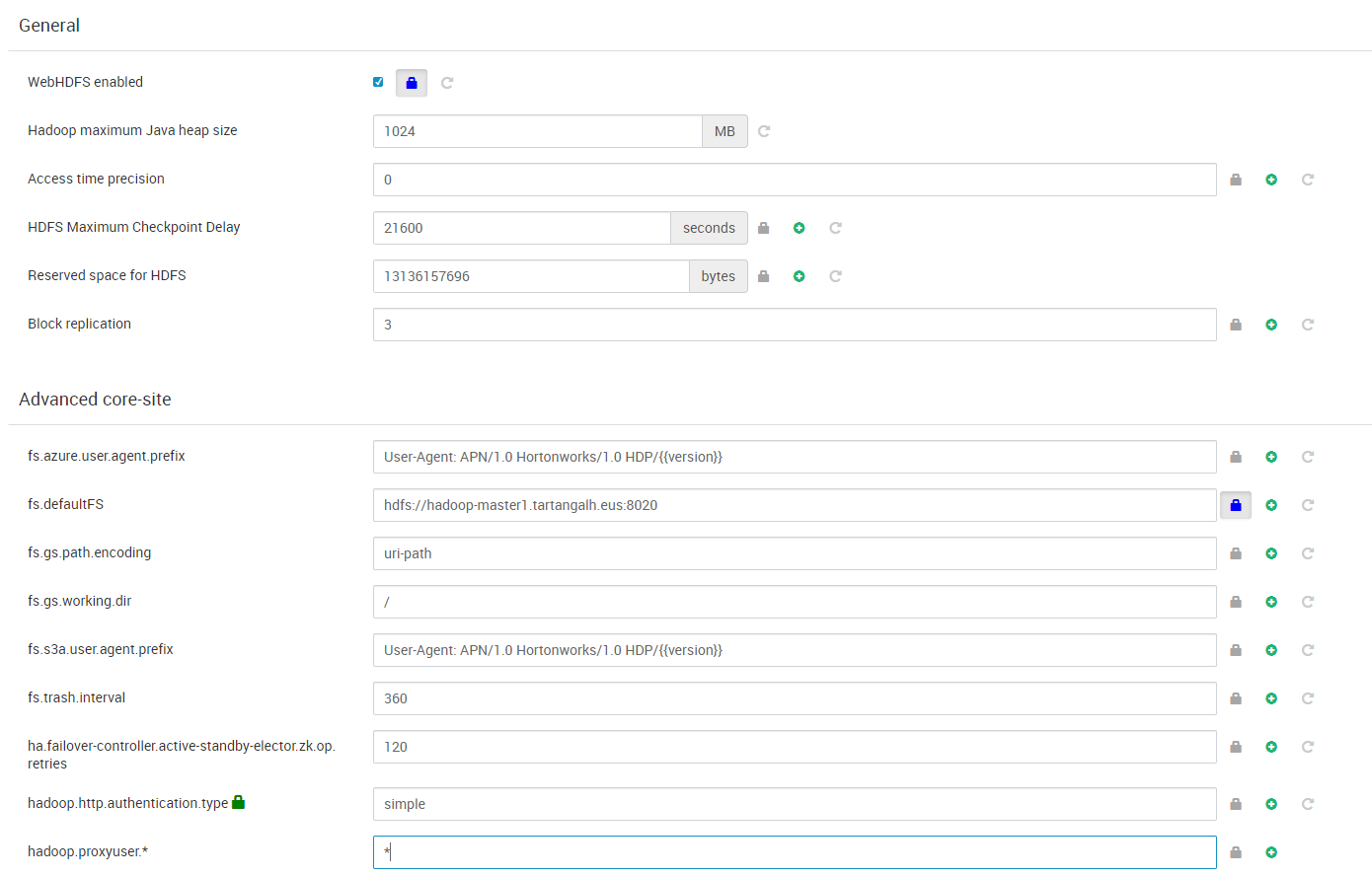
- HDFS: Establecemos o revisamos parámetros generales del sistema de archivos distribuido, como el factor de replicación de bloques o el espacio reservado para uso no-DFS, así como las ubicaciones de los sistemas de archivo (puntos de montaje) en los nodos máster y workers.


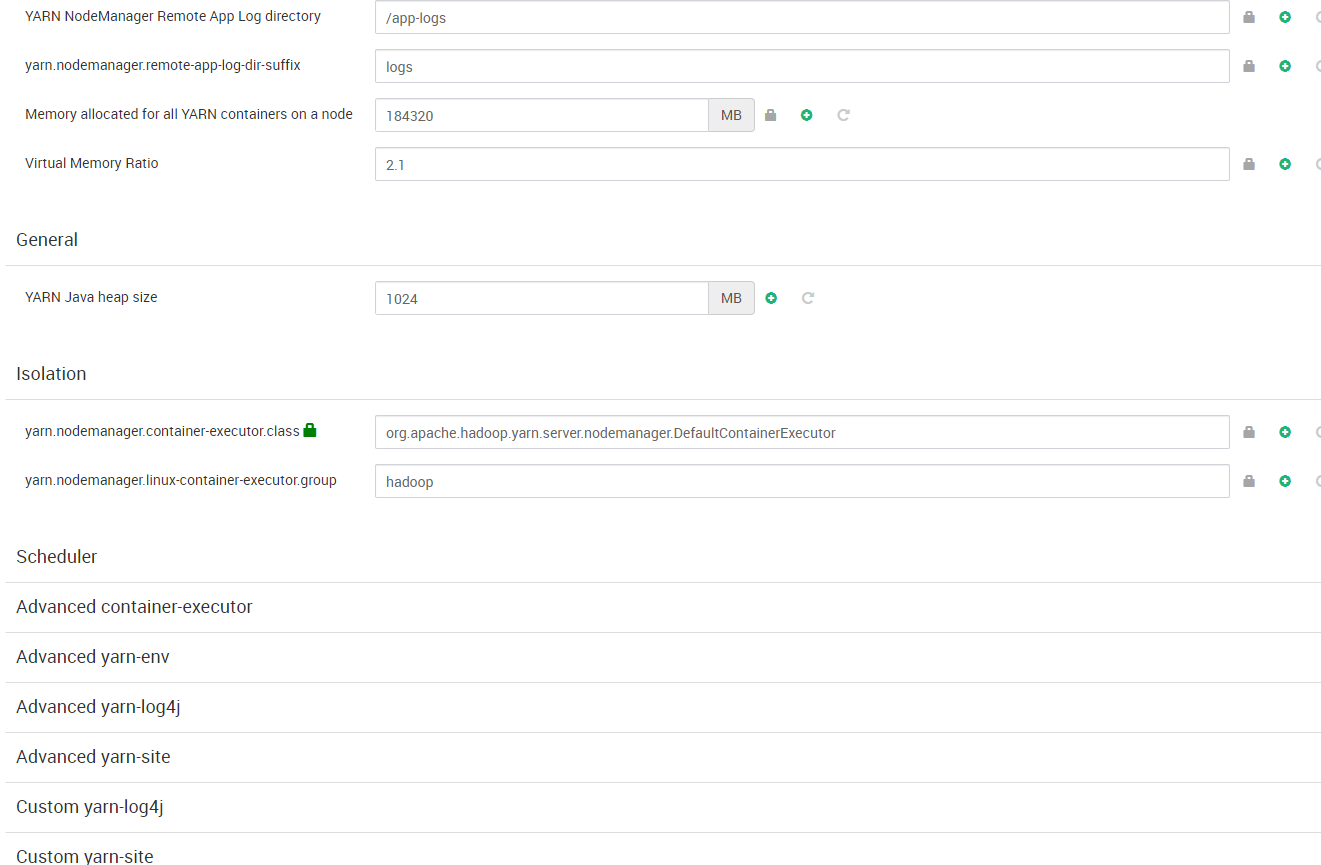
- YARN: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.

- MapReduce: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.

- Tez: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Hive: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.


- HBase: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.


- Zookeeper: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Ambari Metrics: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.

- Kafka: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Spark: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.

- Zeppelin: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Flink :Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Solr: Revisamos los valores de los parámetros sin necesidad, en principio, de modificarlos.
- Credenciales: establecemos las credenciales para usuarios de Grafana y Hive:
- Por último y antes de pasar a la tarea de revisar y desplegar el clúster, revisamos y establecemos, en su caso, las cuentas de usuario que se van a utilizar para los diferentes servicios:

- Lanzamos el asistente de instalación del clúster: