
1 MapReduce
MapReduce es un modelo de programación y un marco de ejecución para resolver problemas de procesamiento de datos masivos.
1.1 Introduccion MapReduce
Hadoop MapReduce es un framework para escribir fácilmente aplicaciones que procesan grandes cantidades de datos en paralelo en grandes clústeres (miles de nodos) de hardware commodity de manera confiable y tolerante a fallos.
- Framework:En MapReduce, los desarrolladores escriben trabajos que consisten principalmente en una función map y una función reduce, y el framework maneja los detalles complejos de paralelizar el trabajo, monitorizar la ejecución o recuperarse ante errores. Debes entender que este tipo de operaciones (monitorización, control de errores, gestión de la concurrencia, etc.) son las más complejas en cualquier sistema de procesamiento masivo de datos, y habitualmente supone el 90% de todo el esfuerzo realizado en el desarrollo de un proceso masivo.De esta manera, los desarrolladores están protegidos de tener que implementar código complejo y repetitivo y, en su lugar, sólo deben centrarse en desarrollar los algoritmos y la lógica de negocio.El framework invoca el código proporcionado por el usuario y no al revés. En este sentido, este paradigma es muy parecido a la mayoría de frameworks de desarrollo web, donde el desarrollador debe desarrollar sólo la lógica de negocio que hay detrás de cada interacción del usuario, y no debe preocuparse en los detalles sobre manejar el protocolo HTTP, la concurrencia de las aplicaciones, la gestión de las sesiones de usuario, etc.
- Grandes Cantidades de Datos:MapReduce está diseñado para poder procesar grandes cantidades de datos, ya que sigue una filosofía Divide y Vencerás (DYV), que consiste en que para resolver un problema complejo, la mejor forma de hacerlo es dividirlo en fragmentos muy pequeños que pueden ser solucionados de forma independiente, resolverlo por separado e ir construyendo con las soluciones parciales la solución final.Para el caso del procesamiento de datos de mucho volumen, la aproximación Divide y Vencerás que hace MapReduce consiste en dividir todo el conjunto de datos de entrada en pequeños fragmentos, procesarlos por separado, e ir agrupando los resultados parciales.
- Paralelo:MapReduce ejecuta el procesamiento de cada elemento por separado y el paralelo, es decir, la ejecución se divide en partes pequeñas y cada parte pequeña se ejecuta en paralelo, lo que facilita la escalabilidad o la tolerancia a fallos.
- Clusteres:MapReduce se ejecuta en paralelo en un modelo de computación distribuida, es decir, cada pieza de ejecución se ejecuta en una máquina diferente, siendo cada máquina un servidor de un clúster Hadoop.YARN se ocupa de los detalles de la ejecución en cuanto a asignación de recursos, nodos disponibles, etc.Asimismo, MapReduce puede ejecutarse en clústers de más de mil nodos, o incluso más, ya que el paradigma no tiene limitaciones en cuanto al número de servidores que pueden ejecutar un trabajo.
- Hardware Commodity:MapReduce no requiere unos servidores específicos para su ejecución. De hecho, ¡emplea los mismos servidores de la plataforma Hadoop!
- Confiable y Tolerante a Fallos:Uno de las principales ventajas de MapReduce frente a otros modelos de programación más eficientes, es que es confiable, es decir, la ejecución de trabajos siempre obtiene los mismos resultados, y además, tiene una capacidad para sobreponerse a fallos muy buena. Durante la ejecución de un trabajo, en caso de que uno de los nodos falle, MapReduce puede recuperar la tarea que dicho nodo estaba ejecutando y reprocesarla con otro nodo activo.En ocasiones se hace el símil de MapReduce con una apisonadora, en el sentido de que es lenta pero segura, y en contraposición con otros frameworks que aunque tienen una velocidad superior, al utilizar elementos como la memoria, que puede ser volátil, u otro tipo de aceleradores, hace que tengan una tasa de fallos superior a MapReduce, y por ello, habitualmente, los procesos pesados que se ejecutan en ventana nocturna, que no requieren un tiempo de procesamiento corto, se confían a MapReduce ya que tiene mayor garantía de finalización correcta.
Aunque MapReduce ha sido utilizado ampliamente por toda la comunidad de desarrolladores o proyectos Big Data, la realidad es que hoy en día cada vez se usa menos. Pero es importante entender y comprender bien MapReduce por dos motivos:
- Utiliza un modelo de programación que es común en otras herramientas o frameworks Big Data.
- Muchas herramientas que se ejecutan sobre Hadoop, como puede ser el caso de Hive, pese a que ofrecen funcionalidad de alto nivel, como puede ser la capacidad de hacer consultas en formato SQL, por debajo ejecutan MapReduce. Entender MapReduce es fundamental para poder depurar o resolver problemas en la ejecución de trabajos con este tipo de herramientas.
1.2 Funcionamiento MapReduce
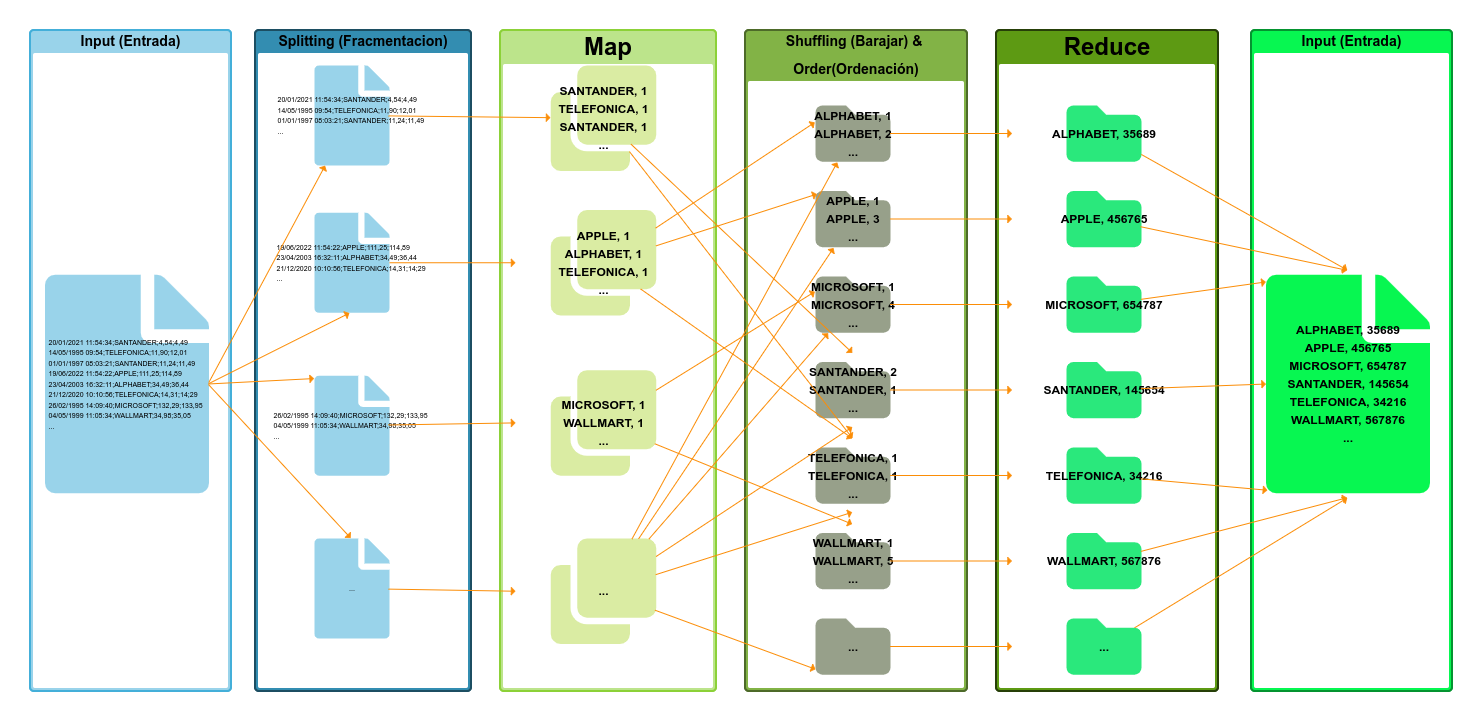
Un trabajo de MapReduce se compone de las siguientes etapas, ejecutadas en orden:
- Input (Entrada): agregación de la información textual que se procesará. Envío del trabajo, aceptación y distribución en el clúster.
- Splitting (Fracmentacion): Proceso de división de los datos.
- Mapping (Mapeo): Mapeo de la información, es decir, la identificación y clasificación de los datos.
- Shuffling (Barajar): Reubicación de los datos según su relación y & Order(Ordenación) oredenación de los datos.
- Reducing (Reducir): La cúspide de su función es reducir. Hadoop MapReduce lleva a cabo su principal objetivo de reducir la información basándose en los parámetros de análisis de datos.
- Final result: Los resultados de la información simplificada.
De todas estas fases debes saber que el programador sólo suele programar la fase map y reduce, siendo el resto de fases ejecutadas de forma automática por MapReduce en base a los parámetros de configuración.
Para explicar el funcionamiento de MapReduce, se va a utilizar el siguiente ejemplo:
Imagina que tenemos un fichero de muchos terabytes de datos con todas las cotizaciones de todas las empresas de todas las bolsas del mundo desde hace 30 años, con una cotización cada minuto.
Tomando una media de 35.000 empresas cotizadas en el mundo, es decir, 35.000 cotizaciones por minuto serían 25.200.000 cotizaciones al día, y un total de 275.940.000.000 líneas en el fichero, que son unos 25 terabytes de datos en un único fichero.
Cada línea del fichero tiene el siguiente formato:
|
1 2 3 4 5 6 7 8 9 |
20/01/2021 11:54:34;SANTANDER;4,54;4,49 14/05/1995 09:54;TELEFONICA;11,90;12,01 01/01/1997 08:03:21;SANTANDER;11,24;11,49 19/06/2022 11:54:22;APPLE;111,25;114,89 23/04/2003 16:32:11;ALPHABET;34,49;36,44 21/12/2020 10:10:56;TELEFONICA;14,31;14;29 26/02/1995 14:09:40;MICROSOFT;132,29;133,95 04/05/1999 11:05:34;WALLMART;34,98;35,05 ... |
Nuestro objetivo es averiguar cuántas veces ha tenido cada empresa un incremento en su cotización, es decir, si una cotización es superior a su valor anterior, sumaremos uno, y si la cotización es inferior, no lo sumaremos.
Es decir, el resultado sería una lista de la siguiente forma:
|
1 2 3 |
SANTANDER 3888981 TELEFONICA 3331923 ... |
Intentar este cálculo leyendo el fichero de forma secuencial y teniendo un contador para cada empresa sería un proceso que llevaría días de procesamiento, así que vamos a utilizar MapReduce para realizar este proceso.
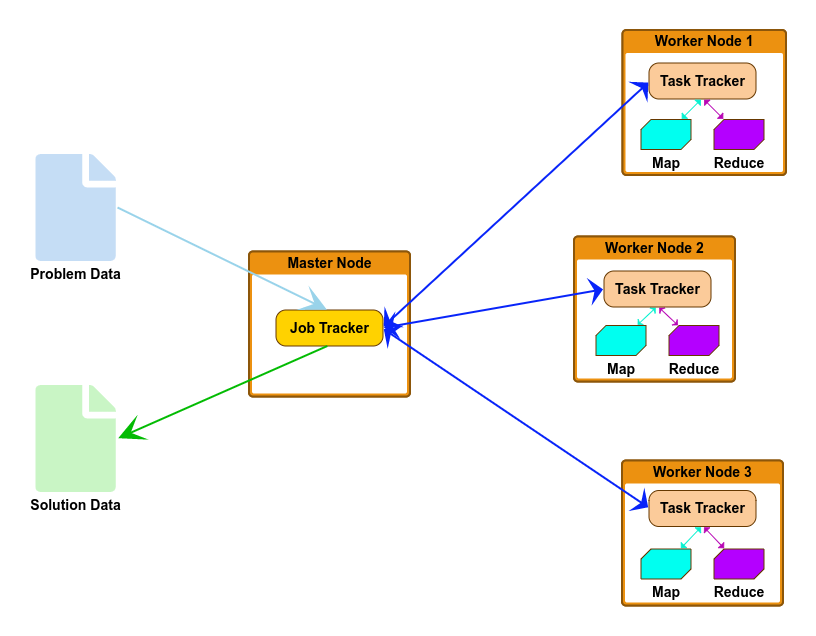
El primer paso es crear la aplicación, utilizando un lenguaje (Java, R, Python …), y enviar el programa al clúster Hadoop utilizando el API de MapReduce para enviar trabajos.
El ResourceManager de YARN tomará el trabajo y en función de la situación del clúster en cuanto al número de contenedores disponibles, arrancará un ApplicationsMaster que lanzará la aplicación MapReduce.
Una vez arrancada la aplicación, en primer lugar decidirá cómo partir el fichero de entrada en fragmentos para que los datos puedan ser procesados en paralelo. El componente que realiza esta división de los ficheros de entrada se denomina InputFormat.
Por cada fragmento del fichero de entrada, se crea una tarea map que ejecutará la función map desarrollada en diferentes nodos y en paralelo, es decir, cada fragmento será procesado en paralelo por diferentes nodos.
La función map toma cada línea, que es separada por el InputFormat, la lee, y emite un resultado parcial, que seá [Nombre de la empresa, 1], en los casos en los que vea que el valor actual es mayor que el valor anterior. Esta función se ejecutará tantas veces como líneas tenga el fragmento de fichero asignado, y en tantos nodos como fragmentos se haya dividido el fichero.
Es decir, para cada nodo, tendremos, este resultado:
|
1 2 3 4 5 6 |
SANTANDER, 1 WALLMART, 1 TELEFONICA, 1 APPLE, 1 ALPHABET, 1 ... |
Y tendremos tantos resultados de estos como fragmentos del fichero haya, y en tantos nodos/servidores como se haya ejecutado la función.
A continuación se ejecutan las fases de shuffle y sort de forma automática y transparente para el desarrollador, donde se toman los resultados parciales, se ordenan por una clave, que en este caso será el nombre de la empresa, se combinan y se ordenan, juntando todos los valores de cada empresa, es decir, teniendo la lista de valores con el siguiente formato:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
ALPHABET, 1 ALPHABET, 2 APPLE, 1 APPLE, 4 APPLE, 1 APPLE, 3 SANTANDER, 1 SANTANDER, 3 SANTANDER, 2 SANTANDER, 1 TELEFONICA, 3 TELEFONICA, 2 TELEFONICA, 1 WALLMART, 4 WALLMART, 2 ... |
Por último, se divide la lista ordenada en diferentes particiones, siendo cada partición un conjunto de datos con la misma clave, y se llaman a la función reduce desarrollada por el usuario, que tomará los diferentes valores emitidos por la fase map, pero ya ordenados y unidos, e irá haciendo la suma de cada empresa, dando como resultado pares [Nombre de la empresa, número de veces que se ha encontrado una cotización incrementada].
MapReduce, por último tomará todos los resultados de las funciones reduce y las unirá, formando el resultado final, que será la lista total de empresas con el número de veces en las que la cotización sube.
2 EJERCICIO:
Ocurrecia de Palabras en un Fichero (Word Count) escrito en distintos lenguajes (R, Python, Pig y Java):
2.1 R:
- WordCount_mapper.R
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount_mapper.R', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
args = commandArgs(trailingOnly=TRUE) trimWhiteSpace <- function(line) gsub("(^ +)|( +$)", "", line) splitIntoWords <- function(line) unlist(strsplit(line, "[[:space:]]+")) if (length(args)>=2){ print('No se le ha llamado desde linea de comandos!') NombreFichero <- args[1] NombreFicheroOutput <- args[2] FInput <- file(NombreFichero) com <- paste("wc -l ", NombreFichero, " | awk '{ print $1 }'", sep="") nLineas <- system(command=com, intern=TRUE) Lineas <- readLines(FInput, n = nLineas, warn = FALSE) ListaResultados <- c() for(i in 1:nLineas) { line <- Lineas[i] line <- trimWhiteSpace(line) words <- splitIntoWords(line) for (w in words){ cat(w, "\t1\n", sep="") Resultado <- sprintf('%s\t1',w) ListaResultados <- c(ListaResultados,Resultado) } } close(FInput) # Escribimos a Fichero Fichero <-file(NombreFicheroOutput) writeLines(ListaResultados, Fichero) close(Fichero) }else{ con <- file("stdin", open = "r") while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0) { line <- trimWhiteSpace(line) words <- splitIntoWords(line) for (w in words){ cat(w, "\t1\n", sep="") } } close(con) } |
- WordCount_reducer.R
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount_reducer.R', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
args = commandArgs(trailingOnly=TRUE) trimWhiteSpace <- function(line) gsub("(^ +)|( +$)", "", line) splitLine <- function(line) { val <- unlist(strsplit(line, "\t")) list(word = val[1], count = as.integer(val[2])) } env <- new.env(hash = TRUE) if (length(args)>=2){ print('No se le ha llamado desde linea de comandos!') NombreFichero <- args[1] NombreFicheroOutput <- args[2] FInput <- file(NombreFichero) com <- paste("wc -l ", NombreFichero, " | awk '{ print $1 }'", sep="") nLineas <- system(command=com, intern=TRUE) Lineas <- readLines(FInput, n = nLineas, warn = FALSE) for(i in 1:nLineas) { line <- Lineas[i] line <- trimWhiteSpace(line) split <- splitLine(line) word <- split$word count <- split$count if (exists(word, envir = env, inherits = FALSE)) { oldcount <- get(word, envir = env) assign(word, oldcount + count, envir = env) }else{ assign(word, count, envir = env) } } close(FInput) ListaResultados <- c() for (w in ls(env, all = TRUE)){ cat(w, "\t", get(w, envir = env), "\n", sep = "") Resultado <- sprintf('%s\t%s',w,get(w, envir = env)) ListaResultados <- c(ListaResultados,Resultado) } # Escribimos a Fichero Fichero <-file(NombreFicheroOutput) writeLines(ListaResultados, Fichero) close(Fichero) }else{ con <- file("stdin", open = "r") while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0) { line <- trimWhiteSpace(line) split <- splitLine(line) word <- split$word count <- split$count if (exists(word, envir = env, inherits = FALSE)) { oldcount <- get(word, envir = env) assign(word, oldcount + count, envir = env) }else{ assign(word, count, envir = env) } } close(con) for (w in ls(env, all = TRUE)){ cat(w, "\t", get(w, envir = env), "\n", sep = "") } } |
- Call_WordCount.R
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/Call_WordCount.R', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
library(callr) # local tesing # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ # echo "foo foo quux labs foo bar quux" | Rscript WordCount_mapper.R if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'Input.txt')) == TRUE){ file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'Input.txt')) } if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputMap.txt')) == TRUE){ file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputMap.txt')) } if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputReduce.txt')) == TRUE){ file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputReduce.txt')) } NombreFicheroInput <- "./MapReduce_Hadoop_Ejemplos/Input.txt" NombreFicheroOutput <- "./MapReduce_Hadoop_Ejemplos/OutputMap.txt" Linea1 <- "Hadoop big machine data learning big data machine Map" Linea2 <- "machine big learning big data machine data data MapReduce" Linea3 <- "Hadoop data Reduce data machine big data machine" Linea4 <- "MapReduce data big big machine big machine big big machine data MapReduce" Linea5 <- "Map Reduce Hadoop MapReduce machine big machine big big machine Map data big MapReduce" Fichero <-file(NombreFicheroInput) writeLines(c(Linea1,Linea2,Linea3,Linea4,Linea5), Fichero) close(Fichero) commandArgs <- c(NombreFicheroInput,NombreFicheroOutput) rscript('./MapReduce_Hadoop_Ejemplos/WordCount_mapper.R', cmdargs = commandArgs, echo = TRUE) # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ # echo "foo foo quux labs foo bar quux" | Rscript WordCount_mapper.R | sort -k1,1 | Rscript WordCount_reducer.R NombreFicheroInput <- "./MapReduce_Hadoop_Ejemplos/OutputMap.txt" NombreFicheroOutput <- "./MapReduce_Hadoop_Ejemplos/OutputReduce.txt" commandArgs <- c(NombreFicheroInput,NombreFicheroOutput) rscript('./MapReduce_Hadoop_Ejemplos/WordCount_reducer.R', cmdargs = commandArgs, echo = TRUE) # File tesing # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ # cat Input.txt | Rscript WordCount_mapper.R # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ # cat Input.txt | Rscript WordCount_mapper.R | sort | Rscript WordCount_reducer.R |
- Ejecucion del Script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
source("./MapReduce_Hadoop_Ejemplos/Call_WordCount.R", echo = TRUE, max.deparse.length = 10000, keep.source = TRUE, prompt.echo = "[INSTRUCCION] >") ## ## [INSTRUCCION] library(callr) ## ## [INSTRUCCION] # local tesing ## [INSTRUCCION] # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ ## [INSTRUCCION] # echo "foo foo quux labs foo bar quux" | Rscript WordCount_mapper.R ## [INSTRUCCION] ## [INSTRUCCION] if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'Input.txt')) == TRUE){ ## + file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'Input.txt')) ## + } ## [1] TRUE ## ## [INSTRUCCION] if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputMap.txt')) == TRUE){ ## + file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputMap.txt')) ## + } ## [1] TRUE ## ## [INSTRUCCION] if (file.exists(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputReduce.txt')) == TRUE){ ## + file.remove(sprintf('%s/MapReduce_Hadoop_Ejemplos/%s',getwd(),'OutputReduce.txt')) ## + } ## [1] TRUE ## ## [INSTRUCCION] NombreFicheroInput <- "./MapReduce_Hadoop_Ejemplos/Input.txt" ## ## [INSTRUCCION] NombreFicheroOutput <- "./MapReduce_Hadoop_Ejemplos/OutputMap.txt" ## ## [INSTRUCCION] Linea1 <- "Hadoop big machine data learning big data machine Map" ## ## [INSTRUCCION] Linea2 <- "machine big learning big data machine data data MapReduce" ## ## [INSTRUCCION] Linea3 <- "Hadoop data Reduce data machine big data machine" ## ## [INSTRUCCION] Linea4 <- "MapReduce data big big machine big machine big big machine data MapReduce" ## ## [INSTRUCCION] Linea5 <- "Map Reduce Hadoop MapReduce machine big machine big big machine Map data big MapReduce" ## ## [INSTRUCCION] Fichero <-file(NombreFicheroInput) ## ## [INSTRUCCION] writeLines(c(Linea1,Linea2,Linea3,Linea4,Linea5), Fichero) ## ## [INSTRUCCION] close(Fichero) ## ## [INSTRUCCION] commandArgs <- c(NombreFicheroInput,NombreFicheroOutput) ## ## [INSTRUCCION] rscript('./MapReduce_Hadoop_Ejemplos/WordCount_mapper.R', cmdargs = commandArgs, echo = TRUE) ## Running /usr/lib/R/bin/Rscript ./MapReduce_Hadoop_Ejemplos/WordCount_mapper.R \ ## ./MapReduce_Hadoop_Ejemplos/Input.txt \ ## ./MapReduce_Hadoop_Ejemplos/OutputMap.txt ## [1] "No se le ha llamado desde linea de comandos!" ## Hadoop 1 ## big 1 ## machine 1 ## data 1 ## learning 1 ## big 1 ## data 1 ## machine 1 ## Map 1 ## machine 1 ## big 1 ## learning 1 ## big 1 ## data 1 ## machine 1 ## data 1 ## data 1 ## MapReduce 1 ## Hadoop 1 ## data 1 ## Reduce 1 ## data 1 ## machine 1 ## big 1 ## data 1 ## machine 1 ## MapReduce 1 ## data 1 ## big 1 ## big 1 ## machine 1 ## big 1 ## machine 1 ## big 1 ## big 1 ## machine 1 ## data 1 ## MapReduce 1 ## Map 1 ## Reduce 1 ## Hadoop 1 ## MapReduce 1 ## machine 1 ## big 1 ## machine 1 ## big 1 ## big 1 ## machine 1 ## Map 1 ## data 1 ## big 1 ## MapReduce 1 ## ## [INSTRUCCION] # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ ## [INSTRUCCION] # echo "foo foo quux labs foo bar quux" | Rscript WordCount_mapper.R | sort -k1,1 | Rscript WordCount_reducer.R ## [INSTRUCCION] ## [INSTRUCCION] NombreFicheroInput <- "./MapReduce_Hadoop_Ejemplos/OutputMap.txt" ## ## [INSTRUCCION] NombreFicheroOutput <- "./MapReduce_Hadoop_Ejemplos/OutputReduce.txt" ## ## [INSTRUCCION] commandArgs <- c(NombreFicheroInput,NombreFicheroOutput) ## ## [INSTRUCCION] rscript('./MapReduce_Hadoop_Ejemplos/WordCount_reducer.R', cmdargs = commandArgs, echo = TRUE) ## Running /usr/lib/R/bin/Rscript \ ## ./MapReduce_Hadoop_Ejemplos/WordCount_reducer.R \ ## ./MapReduce_Hadoop_Ejemplos/OutputMap.txt \ ## ./MapReduce_Hadoop_Ejemplos/OutputReduce.txt ## [1] "No se le ha llamado desde linea de comandos!" ## big 14 ## data 11 ## Hadoop 3 ## learning 2 ## machine 12 ## Map 3 ## MapReduce 5 ## Reduce 2 ## ## [INSTRUCCION] # File tesing ## [INSTRUCCION] # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ ## [INSTRUCCION] # cat Input.txt | Rscript WordCount_mapper.R ## [INSTRUCCION] ## [INSTRUCCION] # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ ## [INSTRUCCION] # cat Input.txt | Rscript WordCount_mapper.R | sort | Rscript WordCount_reducer.R |
2.2 Python:
- WordCount_mapper.py
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount_mapper.py', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# import sys because we need to read and write data to STDIN and STDOUT import sys # reading entire line from STDIN (standard input) for line in sys.stdin: # to remove leading and trailing whitespace line = line.strip() # split the line into words words = line.split() # we are looping over the words array and printing the word # with the count of 1 to the STDOUT for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py print('%s\t%s' % (word, 1)) |
- WordCount_reducer.py
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount_reducer.py', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from operator import itemgetter import sys current_word = None current_count = 0 word = None # read the entire line from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # splitting the data on the basis of tab we have provided in mapper.py word, count = line.split('\t', 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print('%s\t%s' % (current_word, current_count)) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print('%s\t%s' % (current_word, current_count)) |
- Call_WordCount.py
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/Call_WordCount.py', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 |
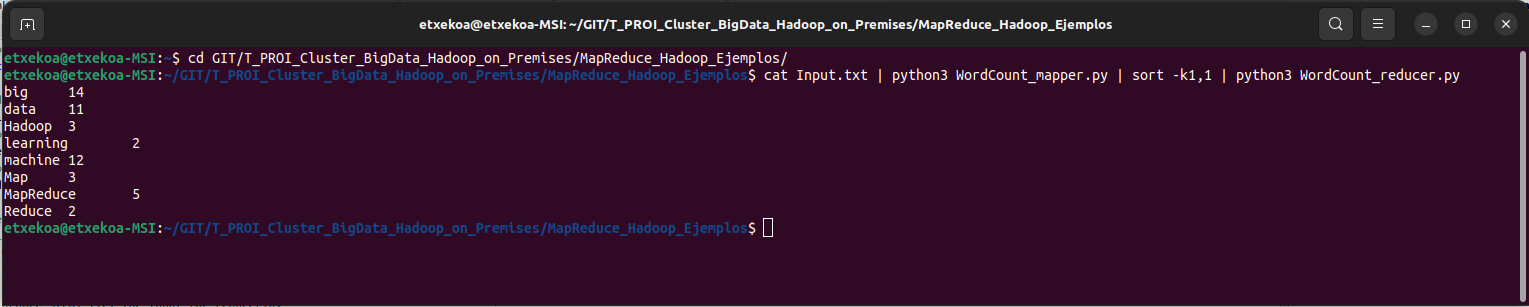
# local testing # cd GIT/T_PROI_Cluster_BigData_Hadoop_on_Premises/MapReduce_Hadoop_Ejemplos/ # cat Input.txt | python3 WordCount_mapper.py | sort -k1,1 | python3 WordCount_reducer.py |
- Ejecucion del Script
2.3 Pig:
- WordCount.pig
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount.pig', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
input_lines = LOAD './MapReduce_Hadoop_Ejemplos/Input.txt' AS (line:chararray); words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word; filtered_words = FILTER words BY word MATCHES '\\w+'; word_groups = GROUP filtered_words BY word; word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group ordered_word_count = ORDER word_count BY count DESC; STORE ordered_word_count INTO './MapReduce_Hadoop_Ejemplos/Output.txt'; -- Explicacion -- 1.- Se abre el fichero sobre el que se quieren contar las ocurrencias de cada palabra. -- 2.- Se separa cada línea en palabras. -- 3.- Se filtran las palabras para eliminar signos o blancos. -- 4.- Se crea un grupo para cada palabra. -- 5.- Cuenta las ocurrencias de cada grupo (de cada palabra). -- 6.- Se ordenan las palabras por ocurrencias. -- 7.- Se almacena la lista de palabras y sus ocurrencias en un fichero. |
2.4 Java:
- WordCount.java
|
1 2 3 |
fichero = open('./MapReduce_Hadoop_Ejemplos/WordCount.java', 'r') archivo = fichero.read() print(archivo) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); }result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |