Comprender y diseñar una política de planificación de recursos de ejecución es una tarea que habrá que afrontar una vez realizado el despliegue del clúster. El objetivo final de esta tarea es prestar a los usuarios finales los recursos de ejecución necesarios para sus trabajos, de acuerdo a la capacidad de nuestro clúster. Como sabemos, el gestor de recursos de procesamiento en Hadoop es YARN y por lo tanto deberemos comprender y aplicar las funciones básicas de su planificador de recursos.
Recursos en YARN: contenedores
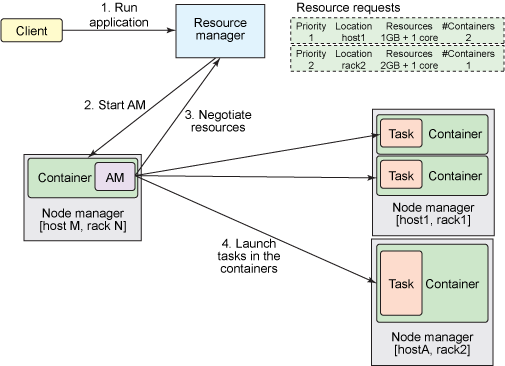
YARN proporciona dos tipos de recurso a las aplicaciones: memoria y núcleos procesadores. Estos dos recursos se integran en unidades llamadas contenedores. Un nodo worker normalmente dispone de una colección de contenedores. Estos contenedores tendrán un tamaño mínimo en cuanto a RAM y número de núcleos y un tamaño máximo hasta el que puede crecer cada contenedor. Un contenedor es supervisado por el NodeManager y planificado por el ResourceManager de YARN.
Cada Aplicación inicia un proceso llamado ApplicationMaster que se ejecuta en un contenedor (contenedor 0). Una vez iniciado, el ApplicationMaster debe negociar con el ResourceManager para obtener más contenedores. Las peticiones y liberaciones de contenedores pueden tener lugar de forma dinámica en tiempo de ejecución. Por ejemplo, un trabajo MapReduce puede solicitar cierta cantidad de contenedores para el mapeo y a medida que finalizan esas tareas de mapeo, puede liberar esos contenedores y solicitar e iniciar más contenedores para la reducción.
Planificación de recursos: colas
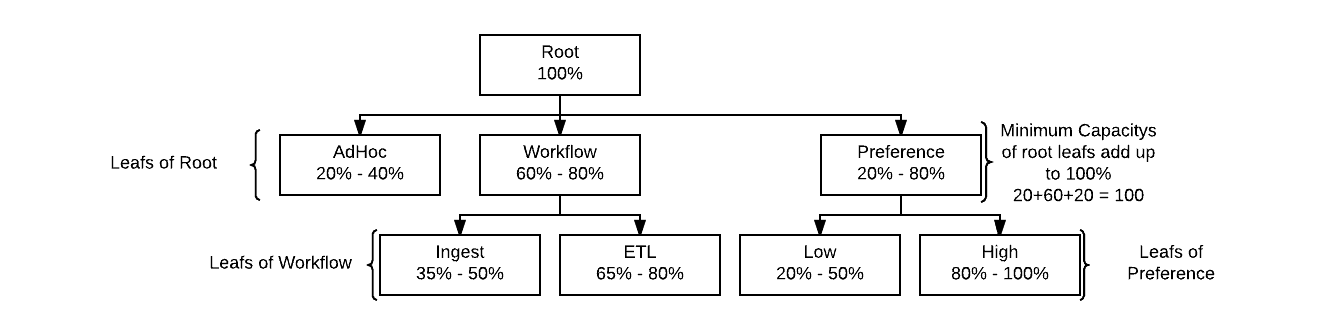
La gestión de recursos en YARN se realiza mediante colas (queues). A estas colas se les asignan recursos en forma un porcentaje de contenedores sobre la capacidad total del clúster. Cada cola puede tener asignados ciertos porcentajes de uso mínimos y máximos diferentes. Podremos, por lo tanto, ejecutar las aplicaciones en diferentes colas de acuerdo a la política de administración de recursos que queramos implementar entre los diferentes, usuarios, grupos u organizaciones que utilicen el clúster. La estructura de colas es jerárquica. La capacidad se asigna a las colas como un porcentaje mínimo y máximo de los recursos de la cola padre en la jerarquía. La capacidad mínima es la cantidad de recursos que la cola debería tener disponibles si el clúster está a tope de uso. La capacidad máxima es una capacidad elástica que permite a las colas hacer uso de recursos que no se están utilizando para alcanzar la demanda de capacidad mínima en dichas colas.
Parámetros fundamentales para la planificación
Existe toda una familia de propiedades (yarn.scheduler.capacity…) del “scheduler” de YARN que permiten la definición y control de nuestras políticas de administración de recursos de ejecución. Las fundamentales, en una primera aproximación, son:
- yarn.scheduler.capacity.root.<queue_hierarchy_route>. capacity: Capacidad mínima de la cola en % sobre la capacidad de la cola padre.
- yarn.scheduler.capacity.root.<queue_hierarchy_route>. maximum-capacity: Capacidad máxima de la cola en % sobre la capacidad de la cola padre.
- yarn.scheduler.capacity.root.<queue_hierarchy_route>. minimum-user-limit-percent: Límite sobre la menor cantidad de recursos a los que un sólo usuario debería tener acceso cuando solicita recursos. Por ejemplo, un valor del 10% significa que 10 usuarios obtendrán, cada uno de ellos, un 10% de los recursos totales de la cola, suponiendo que están solicitándolos; este valor no es rígido en el sentido que si uno de los usuarios pide menos cantidad de recursos se pueden emplazar más usuarios en la cola.
- yarn.scheduler.capacity.root.<queue_hierarchy_route>. user-limit-factor: Es la forma de controlar la máxima cantidad de recursos que un sólo usuario puede consumir. Se establece como un múltiplo de la capacidad mínima de la cola, donde un valor de 1 significa que el usuario puede consumir toda la capacidad mínima de la cola. Si el valor es mayor que 1 el usuario puede crecer en su uso de recursos hasta el máximo de la cola y si es valor es menor de 1, por ejemplo 0.5, el usuario solo podrá obtener la mitad de la capacidad mínima de la cola.
Configuración para nuestro clúster
La configuración de las capacidades para el planificador de YARN de nuestro clúster se ha hecho con el objetivo inicial de proporcionar suficientes recursos a 20 usuarios simultáneos utilizando el 100% de los recursos del clúster.
-
Recursos totales del clúster
Los recursos totales para ejecución en el clúster se componen de memoria RAM y virtual Cores para ejecución. La cantidad de estos recursos para cada nodo trabajador se establecen mediante las propiedades yarn.nodemanager.resource.memory-mb y yarn.nodemanager.resource.cpu-vcores de la configuración de YARN:


-
Contenedores
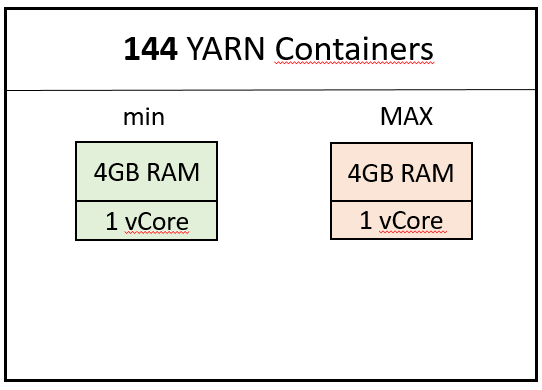
Nuestro clúster dispone de tres nodos worker con 192GB disponibles para Hadoop, lo que hace un total de 576GB de memoria para el clúster. Se han definido los tamaños mínimo (yarn.scheduler.minimum-allocation-mb) y máximo (yarn.scheduler.maximum-allocation-mb) para cada contenedor que, junto con el valor de yarn.nodemanager.resource.cpu-vcores por nodo, definen 144 contenedores para el clúster con los tamaños que se observan en la siguiente figura:
-
Colas
Nuestro clúster dispone de dos colas: iabd y project. La cola iabd está dimensionada para su uso por al menos 20 usuarios simultáneos; su propósito es proporcionar recursos para el mayor número de usuarios posibles. La política de asignación de recursos a aplicaciones en esta cola es FAIR. La cola project está pensada para proporcionar la mayor cantidad de recursos posibles a uno o dos usuarios como máximo.La política de asignación de recursos a aplicaciones en esta cola es FIFO. Los parámetros de cada cola se muestran en la siguiente imagen:
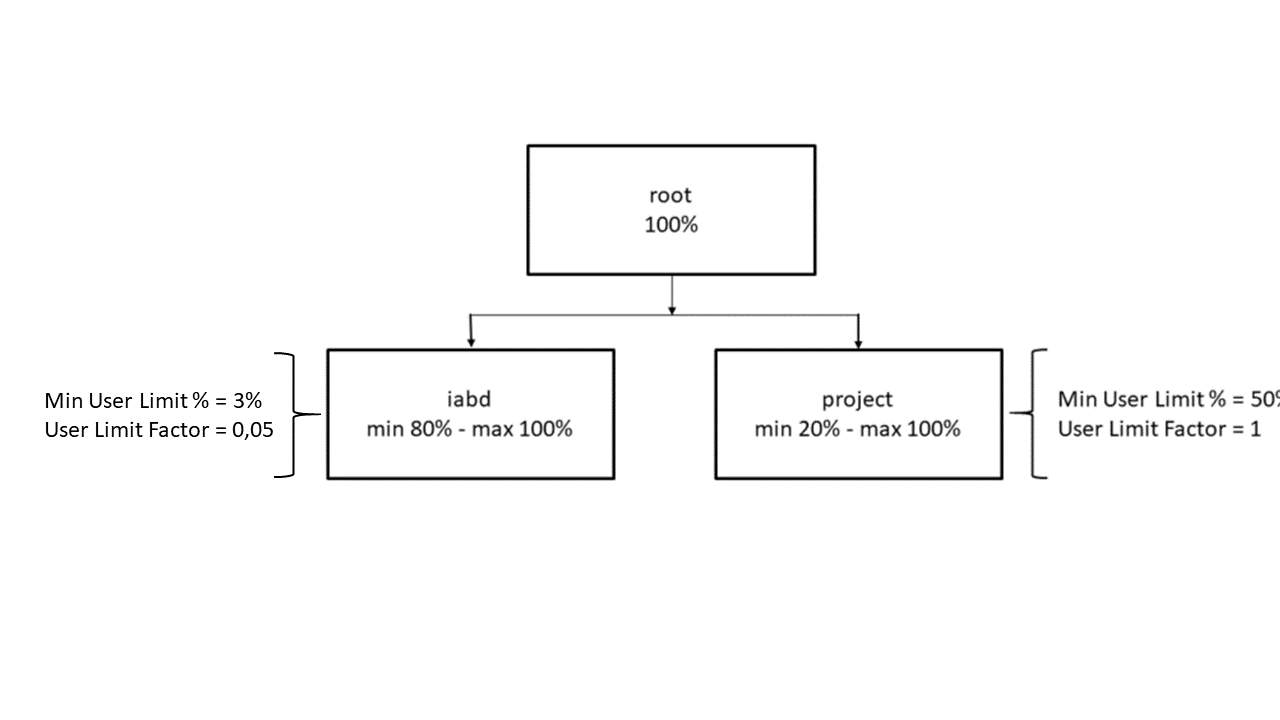
-
Mapeo de colas (Default queue mapping)
- Existe la posibilidad de asignar colas de YARN a usuarios y/o grupos. En nuestro clúster existen los grupos iabd y project a los que se les ha asignado la cola de igual nombre en YARN:
Además mediante las propiedades acl_administer_queue y acl_submit_applications se puede controlar quien (usuarios y/o grupos) puede administrar y enviar trabajos a las colas:1yarn.scheduler.capacity.queue-mappings=g:iabd:iabd,g:project:project
NOTA: Hay que tener en cuenta que en los trabajos MapReduce (MR) la cola de ejecución viene determinada por la propiedad mapreduce.job.queuename que tiene un único valor por defecto, en nuestro caso iabd. Si un usuario ejecuta un trabajo MR este se enviará a dicha cola aunque el usuario no tenga permisos en la acl_submit de YARN. Para enviar el trabajo a otra cola (project) el usuario debe especificarlo al lanzar el trabajo. Por ejemplo:1234yarn.scheduler.capacity.root.iabd.acl_administer_queue=%user,rootyarn.scheduler.capacity.root.iabd.acl_submit_applications=root iabdyarn.scheduler.capacity.root.project.acl_administer_queue=%user,rootyarn.scheduler.capacity.root.project.acl_submit_applications=root project
1yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi -Dmapreduce.job.queuename=project 128 20000000
- Existe la posibilidad de asignar colas de YARN a usuarios y/o grupos. En nuestro clúster existen los grupos iabd y project a los que se les ha asignado la cola de igual nombre en YARN:
-
Pruebas de carga
En las siguientes imágenes puede verse la prueba de carga realizada con 20 usuarios simultáneos ejecutando cada uno el mismo trabajo Spark sobre la cola iabd. Nótese que se ha habilitado la Preemption y la Intra-queue Preemption. Puede observarse que con estos valores se consigue asignar recursos a las aplicaciones de los 20 usuarios (7 contenedores/usuario), con un 95% de uso del clúster y un 118% de la cola iabd.
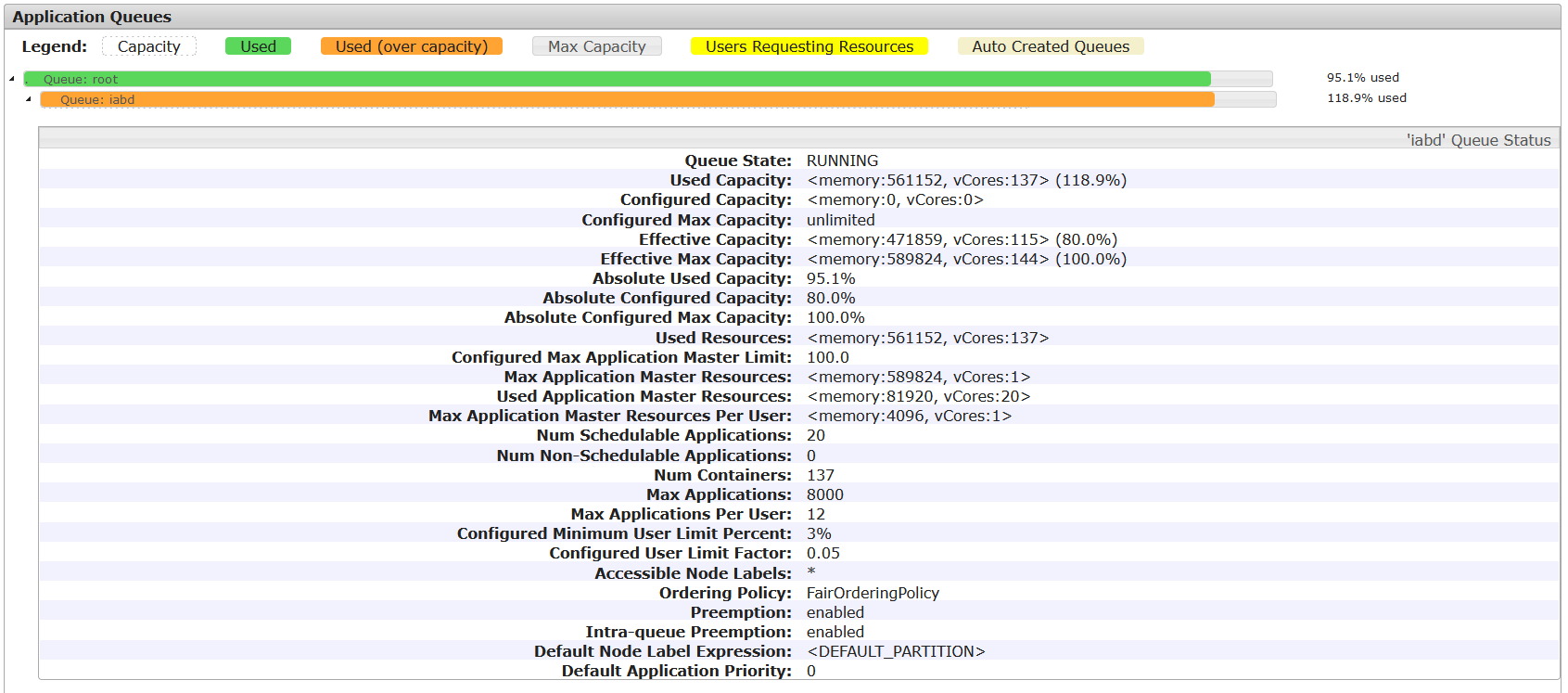
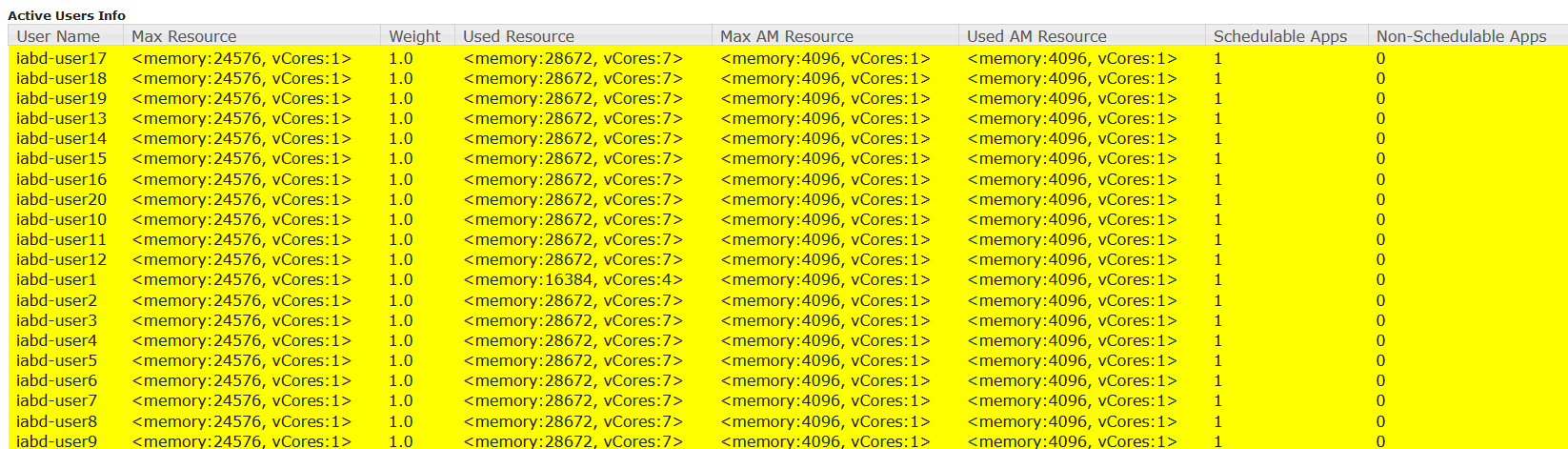
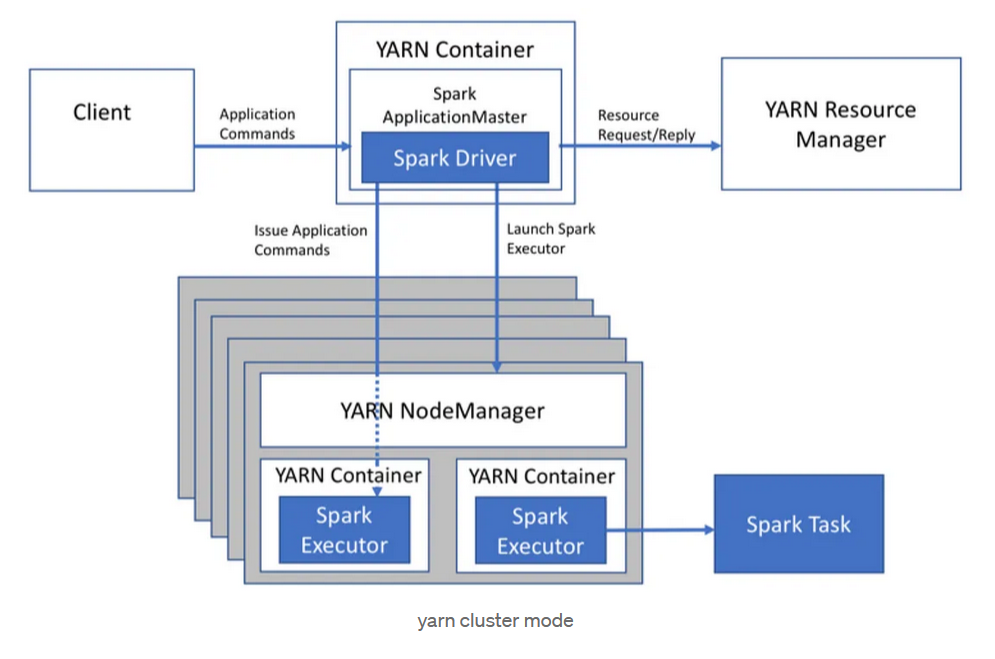
Relación de YARN con instancias de ejecución de otros servicios: Spark y YARN
Los contenedores de YARN contendrán los procesos de otros servicios del clúster que se apoyan en YARN. Estos contenedores deben ser capaces de alojar las instancias de esos otros servicios. Por ello, los tamaños de las instancias deben definirse de forma adecuada al tamaño de los contenedores. Por ejemplo, para Spark, que es uno de los servicios más utilizados en un clúster de este tipo, los tamaños del driver y los executors deben ser apropiados. La siguiente figura muestra la relación de estos elementos en una ejecución de Spark en modo clúster.
En nuestro caso se han definido para Spark un total de 144 instancias para drivers o executors con un tamaño máximo de 3584MB de RAM y 1 vCore.