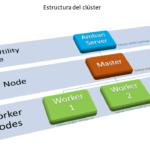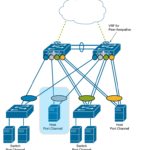
El clúster que se pretende desplegar es un clúster mínimo que físicamente se aloja en un armario rack que contiene los servidores que actúan de nodos del clúster y los dispositivos de conexionado de red (switches) que permiten la comunicación de los nodos. La red de datos que conecta los nodos del clúster es una… Continue reading