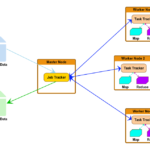
1 MapReduce MapReduce es un modelo de programación y un marco de ejecución para resolver problemas de procesamiento de datos masivos. Apache MapReduce 1.1 Introduccion MapReduce Hadoop MapReduce es un framework para escribir fácilmente aplicaciones que procesan grandes cantidades de datos en paralelo en grandes clústeres (miles de nodos) de hardware commodity de manera confiable… Continue reading