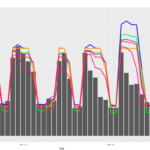
DESCRIPCIÓN Objetivo Cargar datos trasformados del consumo energético en el Clúster para después analizarlos y generar predicciones futuras del consumo Energético. Explicación Los datos de los medidores se registran en una base de datos de Serie Temporal (InfluxDB) registrando el consumo del medidor (kWh) con una frecuencia de 1 minuto. Para obtener los datos del… Continue reading