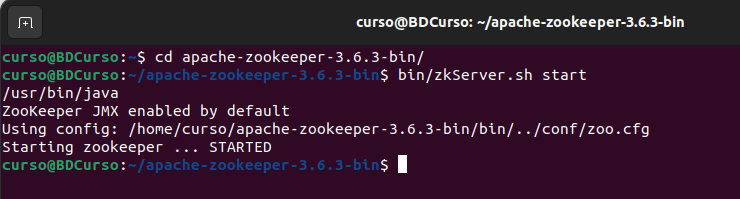
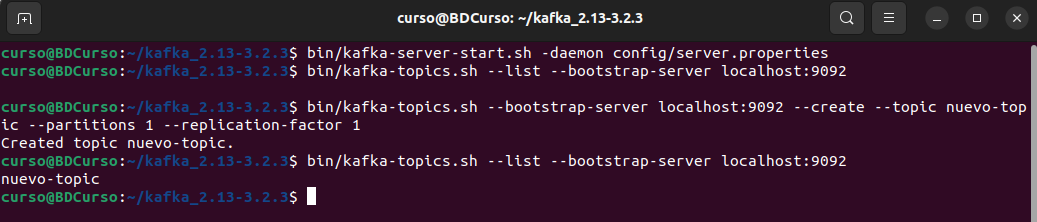
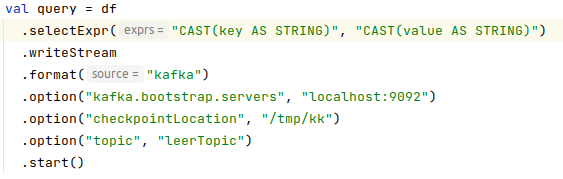
Apache Spark es un marco informático de clúster de código abierto para el procesamiento en tiempo real. Tiene una próspera comunidad de código abierto y es el proyecto Apache más activo en este momento. Spark proporciona una interfaz para programar clústeres completos con paralelismo de datos implícito y tolerancia a fallas.

Fue construido sobre Hadoop MapReduce y extiende el modelo MapReduce para usarlo de manera más eficiente y con más tipos de cálculos.
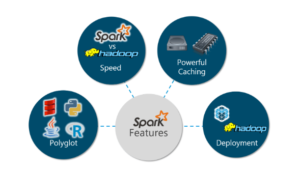
Las característica de Spark son las siguientes:
- Políglota:
- Spark proporciona un API de alto nivel en Java, Scala, Python y R. El código de Spark se puede escribir en cualquiera de estos cuatro lenguajes.
- Proporciona un shell en Scala y en Python.
- Desde el directorio instalado se puede acceder al shell de Scala y al shell de Python a través de ./bin/spark-shell y de ./bin/pyspark respectivamente.
- Velocidad:
- Para el procesamiento de datos a gran escala, Spark se ejecuta hasta 100 veces más rápido que Hadoop MapReduce.
- Spark puede lograr esta velocidad a través de la partición controlada.
- Administra los datos mediante particiones que ayudan a paralelizar el procesamiento de datos distribuidos con un tráfico de red mínimo.
- Evaluación perezosa :
- Apache Spark retrasa su evaluación hasta que sea absolutamente necesario. Este es uno de los factores clave que contribuyen a su velocidad.
- Spark agrega las transformaciones a un DAG (Gráfico acíclico dirigido) de cálculo y solo cuando el controlador solicita algún dato se ejecuta el DAG.
- Integración Hadoop :
- Apache Spark proporciona una compatibilidad fluida con Hadoop.
- Spark es un reemplazo potencial para las funciones de MapReduce de Hadoop.
- Para la programación de recursos, Spark tiene la capacidad de ejecutarse sobre un clúster de Hadoop existente usando YARN.
- Aprendizaje automático :
- MLlib de Spark es el componente de aprendizaje automático, útil cuando se trata de procesamiento de Big Data.
- Erradica la necesidad de usar múltiples herramientas; una para procesamiento y otra para aprendizaje automático.
- Spark proporciona a los ingenieros y científicos de datos un motor potente y unificado rápido y fácil de usar.