
- ¿Qué es ZooKeper?
ZooKeeper es el servicio de coordinación centralizada para aplicaciones distribuidas.
Soluciona problemas como:
- Almacenamiento de configuración.
- Bloqueos distribuidos.
- Elección de líder.
Proporciona una estructura similar a la que se encuentra en un sistema de ficheros.

Cada elemento de la estructura es conocido como Znode y puede contener información en su interior como por ejemplo un JSON.
1.1. ¿Características de ZooKeper?
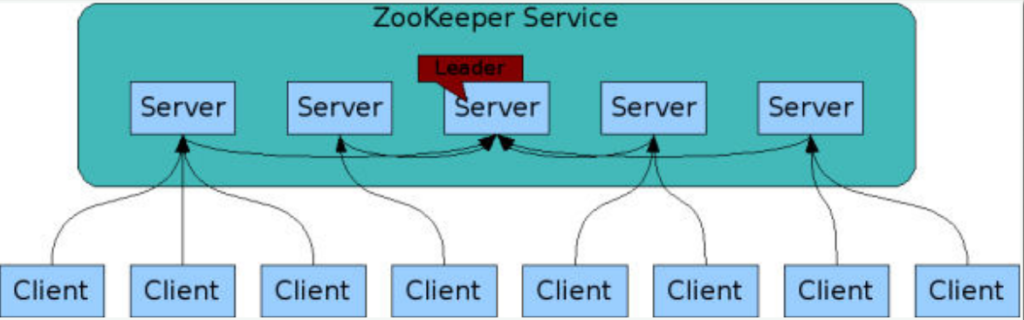
- El servicio esta formado por distintos nodos cada uno con un servidor.
- Uno de los servidores actúa como leader. Encargado de la coordinación interna.
- Siempre tiene que existir Quórum, para validar las escrituras.
- ¿Qué es Kafka?
Kafka es una plataforma de streaming de mensajes diseñada para ser altamente escalable y tolerante a fallos. Es muy utilizada para procesar grandes cantidades de datos en tiempo real y puede ser utilizada en una amplia gama de aplicaciones consumidores.
2.1. Productores y consumidores
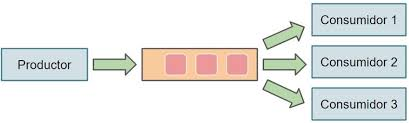
Los productores de Apache Kafka puede ser cualquier aplicación que necesite enviar datos a un sistema distribuido. Son aplicaciones que envían mensajes a uno o varios tópicos de Kafka.
Los consumidores de Kafka son aplicaciones que se suscriben a tópicos de Kafka y procesan los mensajes que se envían a esos tópicos.
En Kafka, las colas se llaman “tópicos” (topics). Los tópicos son similares a las colas tradicionales, pero con algunas diferencias clave. En lugar de tener un único consumidor por mensaje, como ocurre en una cola tradicional, los tópicos de Kafka pueden tener múltiples consumidores que pueden leer los mensajes publicados en el tópico de forma simultánea. Esto permite a Kafka escalar de forma más eficiente y procesar grandes volúmenes de datos de forma rápida.
Además, los tópicos de Kafka tienen un historial de mensajes, lo que significa que se guardan durante un período de tiempo determinado (configurable por el usuario) y pueden ser leídos por cualquier consumidor que se conecte al tópico en cualquier momento durante ese período de tiempo.
2.2. Modelo publicador-suscriptor
El modelo publicador-suscriptor es un patrón de diseño comúnmente utilizado en sistemas de mensajería y se aplica a Kafka en el contexto de tópicos y mensajes.
Kafka utiliza un modelo publicador-suscriptor en el cual existen tres actores principales:
- Publicadores: son los que envían mensajes a un tópico.
- Tópicos: son los que almacenan y distribuyen los mensajes a los suscriptores.
- Suscriptores: son los que reciben los mensajes publicados en un tópico.
Cuando un publicador envía un mensaje a un tópico, el tópico lo almacena y lo distribuye a todos los suscriptores que estén suscritos al tópico. Los suscriptores pueden leer los mensajes en tiempo real mientras se publican o pueden leer los mensajes en un momento posterior.
El modelo publicador-suscriptor permite a los publicadores y suscriptores interactuar de manera asíncrona, lo que significa que no necesitan estar conectados al mismo tiempo para enviar o recibir mensajes. Esto hace que Kafka sea adecuado para aplicaciones que necesitan procesar grandes volúmenes de datos en tiempo real y que pueden tener picos de actividad.
2.3. Brokers
Los brokers de Kafka son los servidores que almacenan y transmiten los mensajes a través de la red. En un cluster de Kafka, puede haber varios brokers para permitir la escalabilidad y la tolerancia a fallos.
Cuando un publicador envía un mensaje a un tópico, el mensaje se almacena en uno o más brokers, dependiendo de la configuración del tópico. Cuando un suscriptor se suscribe a un tópico, los brokers envían los mensajes al suscriptor en tiempo real.
Los brokers también tienen la responsabilidad de replicar los mensajes a través del cluster para garantizar la tolerancia a fallos. Si un broker falla, otro broker puede tomar el control y seguir enviando mensajes a los suscriptores sin interrupción.
Los brokers se sincronizan utilizando Apache ZooKeper.

2.4. Tópicos
Los tópicos de Kafka son los elementos centrales de la plataforma. Son los que almacenan y distribuyen los mensajes publicados por los publicadores a los suscriptores.
Cada tópico tiene un nombre único y puede tener múltiples consumidores que se suscriben a él.
Los mensajes publicados en un tópico se almacenan en el cluster de Kafka y se distribuyen a todos los consumidores suscritos al tópico. Los consumidores pueden leer los mensajes en tiempo real mientras se publican o pueden leer los mensajes en un momento posterior.
Los tópicos también tienen una historia de mensajes, lo que significa que se guardan durante un período de tiempo determinado (configurable por el usuario) y pueden ser leídos por cualquier consumidor que se conecte al tópico en cualquier momento durante ese período de tiempo. Esto hace que Kafka sea útil para el procesamiento de datos en tiempo real y la replicación de datos entre sistemas.
2.4.1. Las particiones
Las particiones de los tópicos de Kafka son una característica clave de la plataforma que permite aumentar la capacidad y la escalabilidad del sistema.
Cada tópico de Kafka se divide en un número configurable de particiones. Cada partición contiene una secuencia ordenada de mensajes y puede almacenar y distribuir mensajes de forma independiente de las otras particiones del mismo tópico. Esto permite a Kafka procesar grandes volúmenes de mensajes de manera eficiente.
En Kafka, la carga se balancea a través de las particiones de los tópicos. Cada tópico se divide en un número configurable de particiones y cada partición puede ser almacenada y replicada en diferentes brokers del cluster.
Cuando un publicador envía un mensaje a un tópico, Kafka distribuye el mensaje a una partición específica del tópico basándose en la clave de partición del mensaje. Esto permite a Kafka distribuir los mensajes de forma equilibrada entre las particiones y aumentar la capacidad del sistema.
Cuando un consumidor se suscribe a un tópico, puede leer los mensajes de cualquiera de las particiones del tópico. Esto permite a los consumidores procesar los mensajes de forma paralela y aumentar la velocidad de procesamiento.
Cada partición es un fichero que se encuentra en el disco.
- Los ficheros son denominados logs.
- Internamente cada mensaje dentro de log es identificado por un offset.
2.4.2. Las replicas
En Kafka, las réplicas son copias de seguridad de las particiones de los tópicos. Cada partición de un tópico puede tener un número configurable de replicas, que se almacenan en diferentes brokers del cluster.
Las replicas tienen dos funciones principales:
- Proporcionar tolerancia a fallos: Si un broker falla, otra replica de la partición puede tomar el control y seguir proporcionando acceso a los mensajes de la partición. Esto permite a Kafka garantizar la disponibilidad de los mensajes incluso en caso de fallos.
- Mejorar la rendimiento: Las replicas permiten a los consumidores leer los mensajes de forma paralela de diferentes brokers, lo que aumenta la velocidad de procesamiento y el rendimiento del sistema.
Kafka gestiona las replicas de forma automática y puede replicar las particiones a través de diferentes brokers del cluster para garantizar la tolerancia a fallos y el rendimiento. El usuario puede configurar el número de replicas de cada partición y Kafka se encargará de mantenerlas sincronizadas y actualizadas.
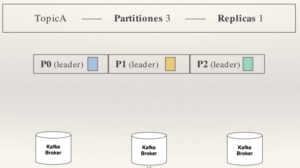
Un tópico con 3 particiones, que cada una de ellas va a un broker, y no hay réplicas:

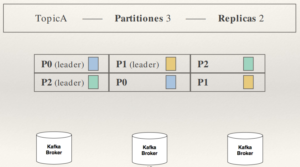
Un tópico con 3 particiones, que cada una de ellas va a un broker, y 2 réplicas:


Un tópico con 3 particiones, que cada una de ellas va a un broker, y 3 réplicas:
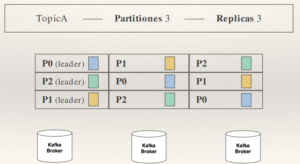

Máximas replicas == Numero de brokers.
❖ Al incrementar las replicas hacemos el sistema mas robusto ante caídas.
❖ Las replicas implican un incremento del uso del ancho de banda entre los brokers.
❖ Las réplicas provocan la disminución de la tasa de producción de mensajes por segundos a un topic, si se activa el asentimiento por replica.