
Este workshop pretende trabajar con el alumnado del curso de especialización de IA y Big Data las técnicas de acceso básico y uso del clúster Hadoop de Tartanga.

Este workshop pretende trabajar con el alumnado del curso de especialización de IA y Big Data las técnicas de acceso básico y uso del clúster Hadoop de Tartanga.
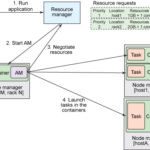
Comprender y diseñar una política de planificación de recursos de ejecución es una tarea que habrá que afrontar una vez realizado el despliegue del clúster. El objetivo final de esta tarea es prestar a los usuarios finales los recursos de ejecución necesarios para sus trabajos, de acuerdo a la capacidad de nuestro clúster. Como sabemos,… Continue reading

En este diagrama se describe brevemente como se relacionan los diferentes elementos que se utilizan en Ambari para la definición y almacenamiento de las configuraciones de los servicios del clúster.

La charla se desarrolló de acuerdo a los siguientes puntos: Introducción a Big Data y Hadoop, Consideraciones técnicas y problemas de despliegue, Documentación del proceso, Servicios del clúster, Uso del clúster: ejecución de trabajos, Coloquio.