
Este workshop pretende trabajar con el alumnado del curso de especialización de IA y Big Data las técnicas de acceso básico y uso del clúster Hadoop de Tartanga.

Este workshop pretende trabajar con el alumnado del curso de especialización de IA y Big Data las técnicas de acceso básico y uso del clúster Hadoop de Tartanga.
Comprender y diseñar una política de planificación de recursos de ejecución es una tarea que habrá que afrontar una vez realizado el despliegue del clúster. El objetivo final de esta tarea es prestar a los usuarios finales los recursos de ejecución necesarios para sus trabajos, de acuerdo a la capacidad de nuestro clúster. Como sabemos, el gestor de recursos de procesamiento en Hadoop es YARN y por lo tanto deberemos comprender y aplicar las funciones básicas de su planificador de recursos.
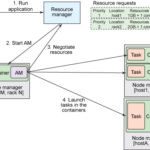
YARN proporciona dos tipos de recurso a las aplicaciones: memoria y núcleos procesadores. Estos dos recursos se integran en unidades llamadas contenedores. Un nodo worker normalmente dispone de una colección de contenedores. Estos contenedores tendrán un tamaño mínimo en cuanto a RAM y número de núcleos y un tamaño máximo hasta el que puede crecer cada contenedor. Un contenedor es supervisado por el NodeManager y planificado por el ResourceManager de YARN.
Cada Aplicación inicia un proceso llamado ApplicationMaster que se ejecuta en un contenedor (contenedor 0). Una vez iniciado, el ApplicationMaster debe negociar con el ResourceManager para obtener más contenedores. Las peticiones y liberaciones de contenedores pueden tener lugar de forma dinámica en tiempo de ejecución. Por ejemplo, un trabajo MapReduce puede solicitar cierta cantidad de contenedores para el mapeo y a medida que finalizan esas tareas de mapeo, puede liberar esos contenedores y solicitar e iniciar más contenedores para la reducción.
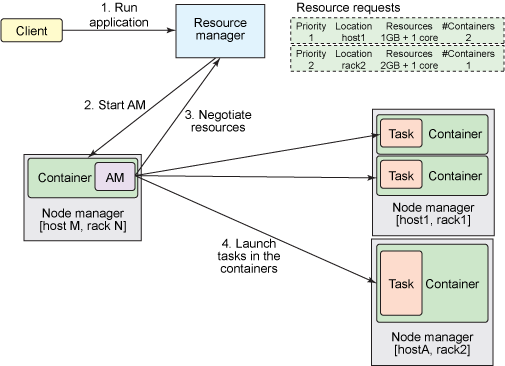
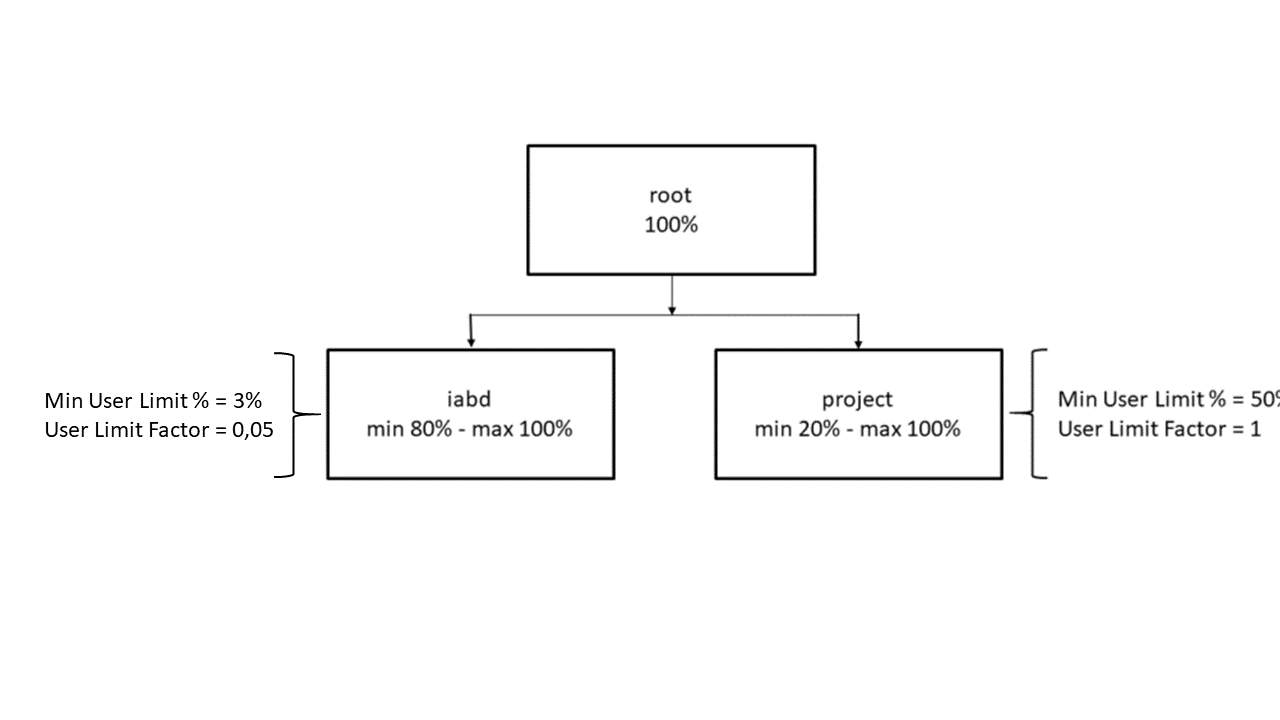
La gestión de recursos en YARN se realiza mediante colas (queues). A estas colas se les asignan recursos en forma un porcentaje de contenedores sobre la capacidad total del clúster. Cada cola puede tener asignados ciertos porcentajes de uso mínimos y máximos diferentes. Podremos, por lo tanto, ejecutar las aplicaciones en diferentes colas de acuerdo a la política de administración de recursos que queramos implementar entre los diferentes, usuarios, grupos u organizaciones que utilicen el clúster. La estructura de colas es jerárquica. La capacidad se asigna a las colas como un porcentaje mínimo y máximo de los recursos de la cola padre en la jerarquía. La capacidad mínima es la cantidad de recursos que la cola debería tener disponibles si el clúster está a tope de uso. La capacidad máxima es una capacidad elástica que permite a las colas hacer uso de recursos que no se están utilizando para alcanzar la demanda de capacidad mínima en dichas colas.
Existe toda una familia de propiedades (yarn.scheduler.capacity…) del “scheduler” de YARN que permiten la definición y control de nuestras políticas de administración de recursos de ejecución. Las fundamentales, en una primera aproximación, son:
La configuración de las capacidades para el planificador de YARN de nuestro clúster se ha hecho con el objetivo inicial de proporcionar suficientes recursos a 20 usuarios simultáneos utilizando el 100% de los recursos del clúster.
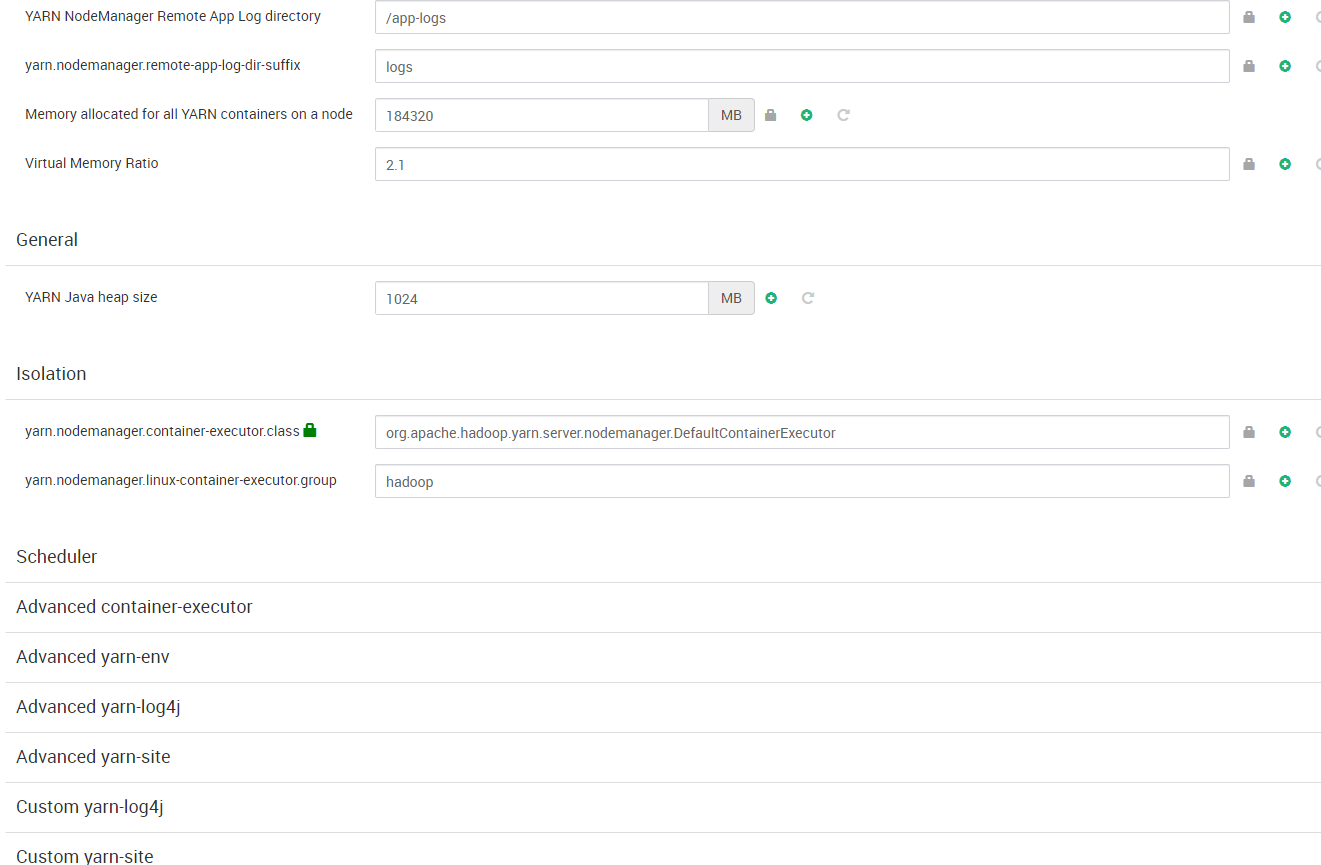
Los recursos totales para ejecución en el clúster se componen de memoria RAM y virtual Cores para ejecución. La cantidad de estos recursos para cada nodo trabajador se establecen mediante las propiedades yarn.nodemanager.resource.memory-mb y yarn.nodemanager.resource.cpu-vcores de la configuración de YARN:


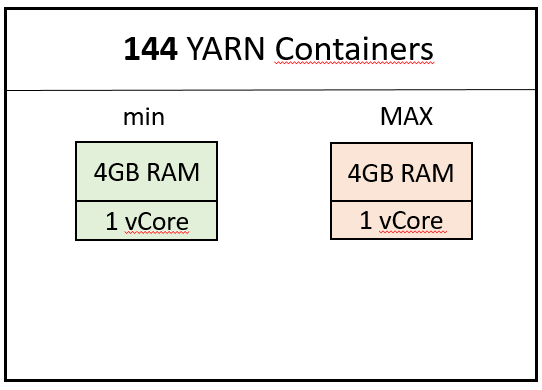
Nuestro clúster dispone de tres nodos worker con 192GB disponibles para Hadoop, lo que hace un total de 576GB de memoria para el clúster. Se han definido los tamaños mínimo (yarn.scheduler.minimum-allocation-mb) y máximo (yarn.scheduler.maximum-allocation-mb) para cada contenedor que, junto con el valor de yarn.nodemanager.resource.cpu-vcores por nodo, definen 144 contenedores para el clúster con los tamaños que se observan en la siguiente figura:
Nuestro clúster dispone de dos colas: iabd y project. La cola iabd está dimensionada para su uso por al menos 20 usuarios simultáneos; su propósito es proporcionar recursos para el mayor número de usuarios posibles. La política de asignación de recursos a aplicaciones en esta cola es FAIR. La cola project está pensada para proporcionar la mayor cantidad de recursos posibles a uno o dos usuarios como máximo.La política de asignación de recursos a aplicaciones en esta cola es FIFO. Los parámetros de cada cola se muestran en la siguiente imagen:
|
1 |
yarn.scheduler.capacity.queue-mappings=g:iabd:iabd,g:project:project |
|
1 2 3 4 |
yarn.scheduler.capacity.root.iabd.acl_administer_queue=%user,root yarn.scheduler.capacity.root.iabd.acl_submit_applications=root iabd yarn.scheduler.capacity.root.project.acl_administer_queue=%user,root yarn.scheduler.capacity.root.project.acl_submit_applications=root project |
|
1 |
yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi -Dmapreduce.job.queuename=project 128 20000000 |
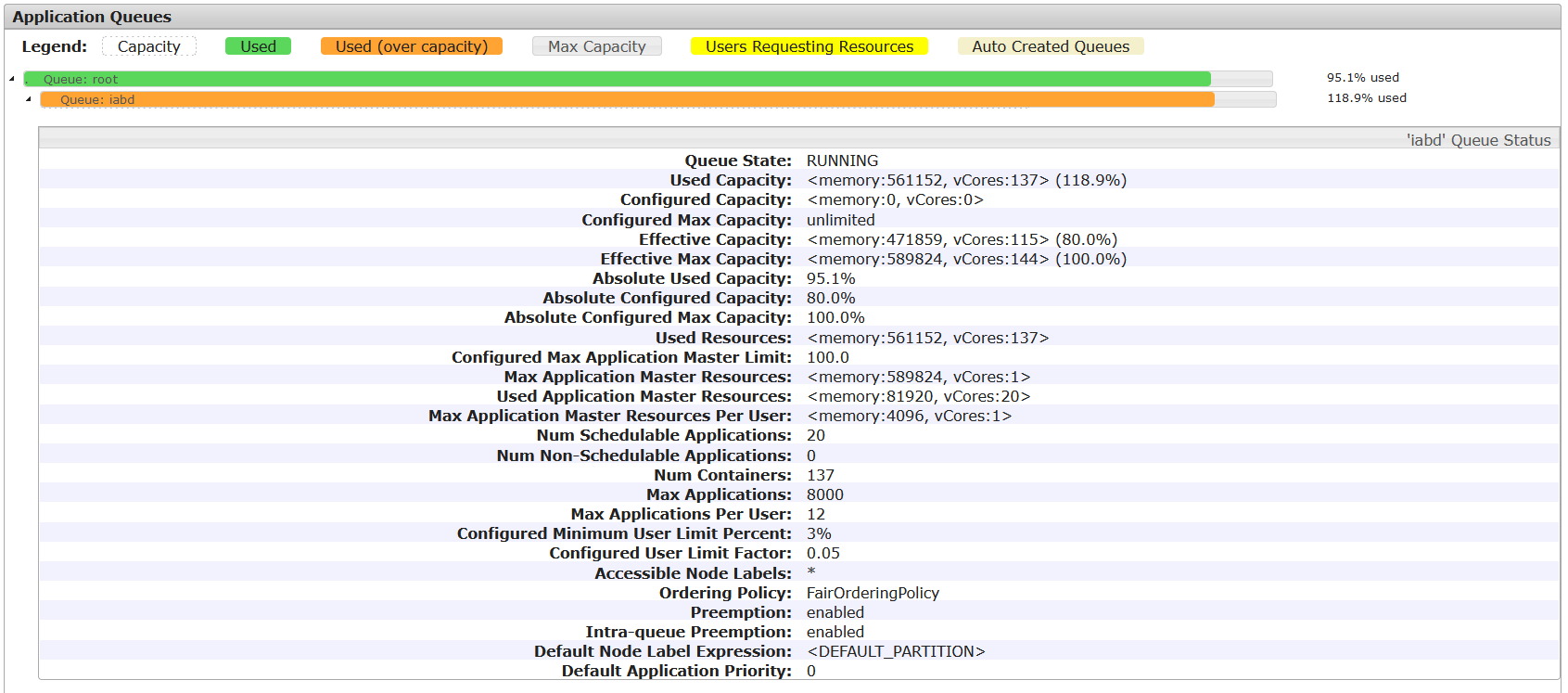
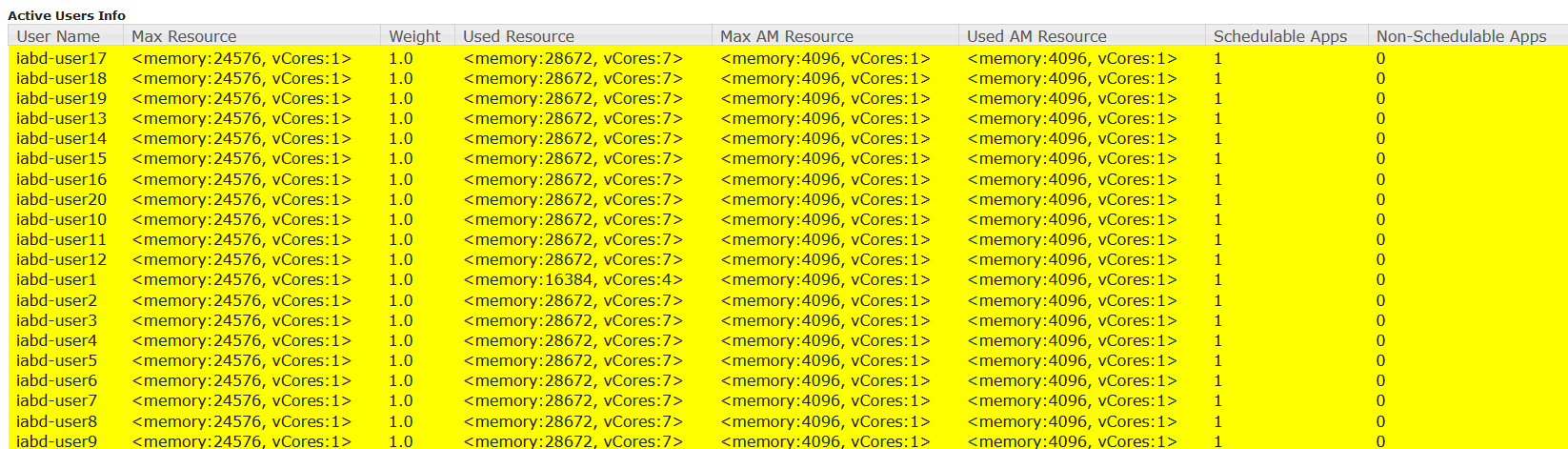
En las siguientes imágenes puede verse la prueba de carga realizada con 20 usuarios simultáneos ejecutando cada uno el mismo trabajo Spark sobre la cola iabd. Nótese que se ha habilitado la Preemption y la Intra-queue Preemption. Puede observarse que con estos valores se consigue asignar recursos a las aplicaciones de los 20 usuarios (7 contenedores/usuario), con un 95% de uso del clúster y un 118% de la cola iabd.
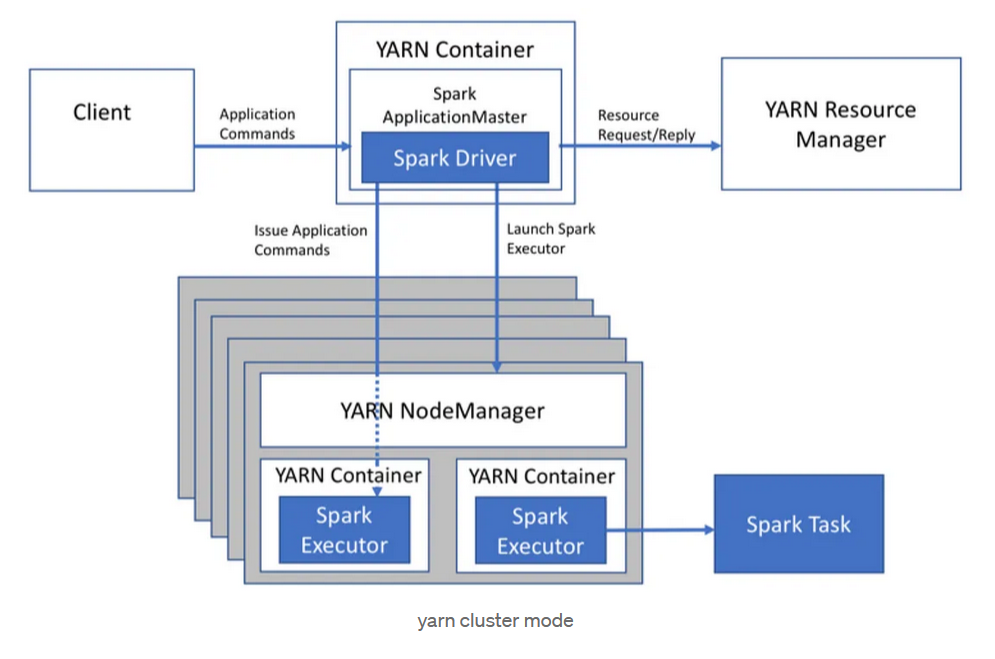
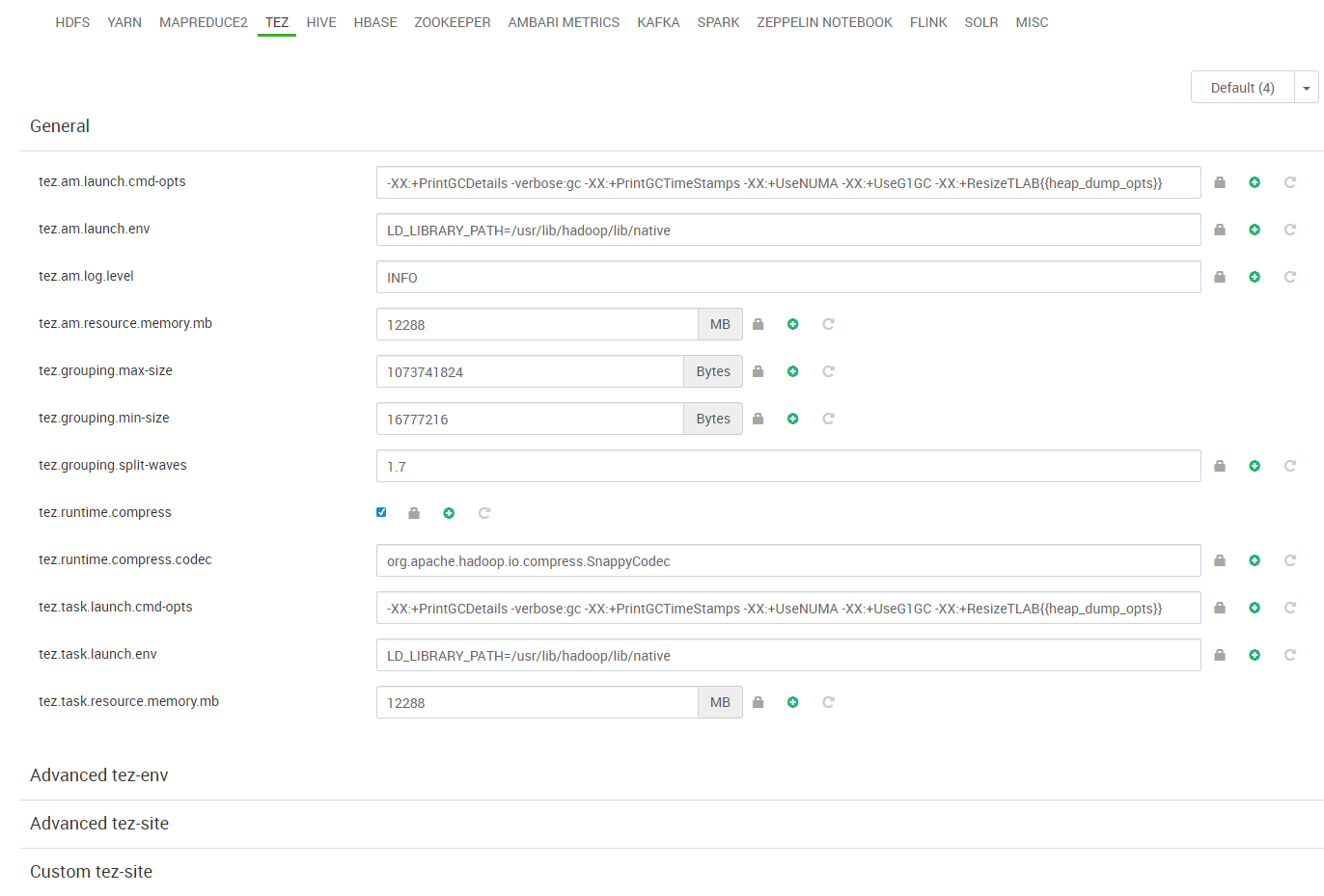
Los contenedores de YARN contendrán los procesos de otros servicios del clúster que se apoyan en YARN. Estos contenedores deben ser capaces de alojar las instancias de esos otros servicios. Por ello, los tamaños de las instancias deben definirse de forma adecuada al tamaño de los contenedores. Por ejemplo, para Spark, que es uno de los servicios más utilizados en un clúster de este tipo, los tamaños del driver y los executors deben ser apropiados. La siguiente figura muestra la relación de estos elementos en una ejecución de Spark en modo clúster.
En nuestro caso se han definido para Spark un total de 144 instancias para drivers o executors con un tamaño máximo de 3584MB de RAM y 1 vCore.

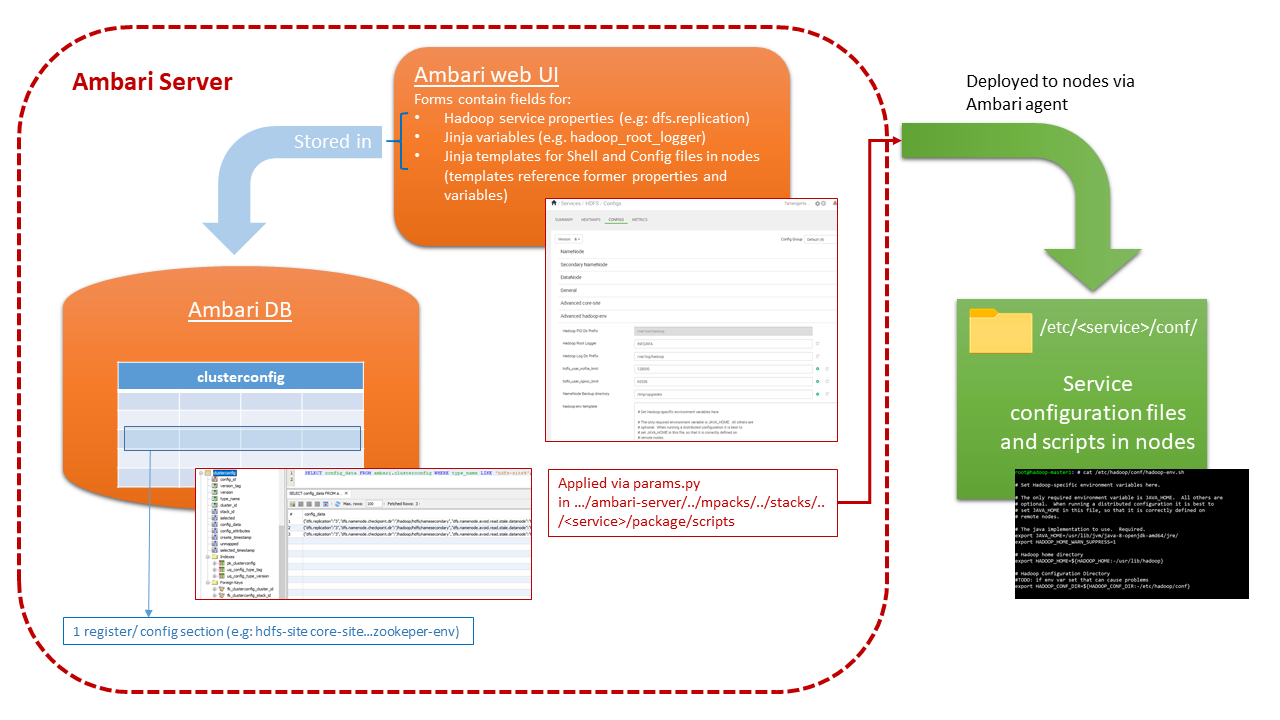
En este diagrama se describe brevemente como se relacionan los diferentes elementos que se utilizan en Ambari para la definición y almacenamiento de las configuraciones de los servicios del clúster.

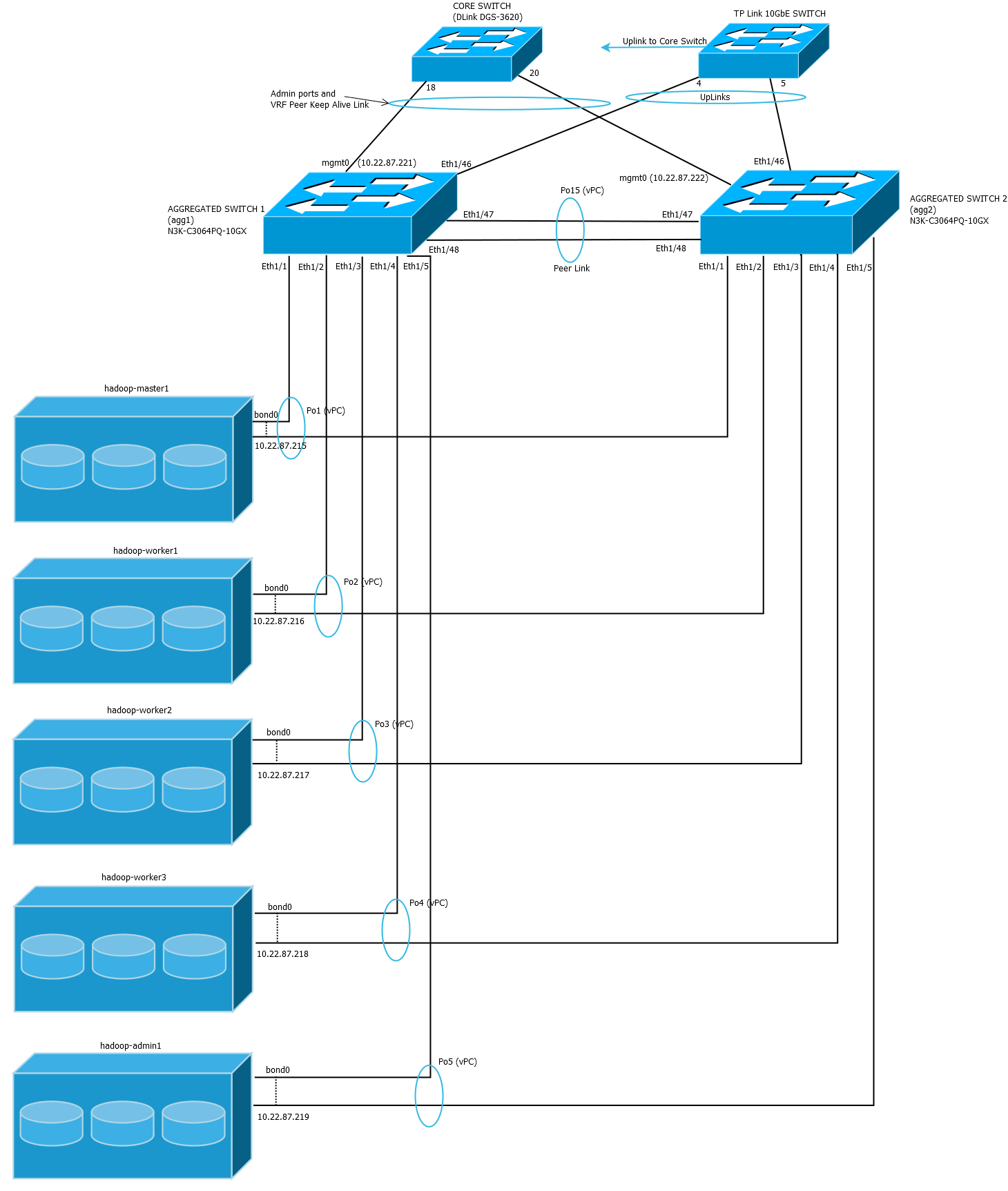
La red de datos que conecta los nodos del clúster es una red de alta velocidad en la que cada nodo dispone de dos NIC Ethernet agregadas (“bonded”) mediante LACP. Este enlace agregado proporciona el doble de ancho de banda y tolerancia a fallos, en caso de que uno de los enlaces individuales falle. Cada enlace individual estará conectado a sendos switches CISCO Nexus de la serie 3000 (concretamente N3K-C3064PQ-10GX) que componen un dominio vPC (virtual PortChannel). En la siguiente figura puede observarse esta estructura, destacada en azul, entre varias configuraciones típicas de conexionado vPC:

Para implementar el Host Port Channel en los servers se han de agregar mediante “bonding” las dos NIC estableciendo los siguientes parámetros:
Configuración switches vPC (virtual PortChannel)
Vamos a configurar la agregación de switches para nuestra red de alta velocidad. Tenga en cuenta que hay que realizar las configuraciones en los dos switches agregados (agg1 y agg2)
Los pasos a realizar son:
|
1 2 3 4 |
agg1#configure terminal agg1#write erase agg1#reload agg1#skip |
|
1 2 3 4 |
agg1#username admin password agg1#hostname agg1 agg1#exit agg1#copy run start |
|
1 2 3 4 |
agg1#interface mgmt0 agg1#ip address 10.22.87.221/24 agg1#no shut agg1#copy run start |
|
1 2 |
agg1#feature vpc agg1#feature lacp |
|
1 2 3 4 |
agg1#interface mgmt0 agg1#vrf member management agg1#exit agg1#ping 10.22.87.221 vrf management |
|
1 2 3 4 5 6 7 8 |
agg1#vpc domain 10 agg1#role priority 100 agg1#peer-keepalive destination 10.22.87.222 source 10.22.87.221 vrf management agg1#peer-gateway agg1#auto-recovery agg1#ip arp synchronize agg1#ipv6 nd synchronize agg1#exit |
peer-keepalive han de intercambiarse para el switch agg2.
|
1 2 3 4 5 6 7 8 9 10 11 |
agg1#interface eth1/47-48 agg1#description **vPC Peer-link** agg1#channel-group 15 mode active agg1#no shut agg1#exit agg1#int port-channel 15 agg1#description **vPC Peer-link** agg1#no shut agg1#switchport agg1#switchport mode trunk agg1#vpc peer-link |
|
1 2 3 4 5 6 7 |
agg1# interface ethernet1/4 agg1# channel-group 4 mode active agg1# no shut agg1# interface port-channel 4 agg1# switchport agg1# vpc 4 agg1# no shut |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
agg1# show vpc brief Legend: (*) - local vPC is down, forwarding via vPC peer-link vPC domain id : 10 Peer status : peer adjacency formed ok vPC keep-alive status : peer is alive Configuration consistency status : success Per-vlan consistency status : success Type-2 consistency status : success vPC role : primary Number of vPCs configured : 5 Peer Gateway : Enabled Dual-active excluded VLANs : - Graceful Consistency Check : Enabled Auto-recovery status : Enabled, timer is off.(timeout = 240s) Delay-restore status : Timer is off.(timeout = 30s) Delay-restore SVI status : Timer is off.(timeout = 10s) Operational Layer3 Peer-router : Disabled Virtual-peerlink mode : Disabled vPC Peer-link status --------------------------------------------------------------------- id Port Status Active vlans -- ---- ------ ------------------------------------------------- 1 Po15 up 1,999 vPC status ---------------------------------------------------------------------------- Id Port Status Consistency Reason Active vlans -- ------------ ------ ----------- ------ --------------- 1 Po1 up success success 999 2 Po2 up success success 999 3 Po3 up success success 999 4 Po4 up success success 999 5 Po5 up success success 999 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
agg2# show vpc brief Legend: (*) - local vPC is down, forwarding via vPC peer-link vPC domain id : 10 Peer status : peer adjacency formed ok vPC keep-alive status : peer is alive Configuration consistency status : success Per-vlan consistency status : success Type-2 consistency status : success vPC role : secondary Number of vPCs configured : 5 Peer Gateway : Enabled Dual-active excluded VLANs : - Graceful Consistency Check : Enabled Auto-recovery status : Enabled, timer is off.(timeout = 240s) Delay-restore status : Timer is off.(timeout = 30s) Delay-restore SVI status : Timer is off.(timeout = 10s) Operational Layer3 Peer-router : Disabled Virtual-peerlink mode : Disabled vPC Peer-link status --------------------------------------------------------------------- id Port Status Active vlans -- ---- ------ ------------------------------------------------- 1 Po15 up 1,999 vPC status ---------------------------------------------------------------------------- Id Port Status Consistency Reason Active vlans -- ------------ ------ ----------- ------ --------------- 1 Po1 up success success 999 2 Po2 up success success 999 3 Po3 up success success 999 4 Po4 up success success 999 5 Po5 up success success 999 |

El primer paso es instalar los paquetes binarios de PostgreSQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# apt install postgresql Reading package lists... Done Building dependency tree Reading state information... Done The following packages were automatically installed and are no longer required: bigtop-groovy bigtop-jsvc bigtop-utils hadoop hadoop-hdfs libevent-core-2.1-7 libevent-pthreads -2.1-7 libopts25 libssl-dev sntp zookeeper Use 'apt autoremove' to remove them. The following additional packages will be installed: libllvm10 libpq5 postgresql-12 postgresql-client-12 postgresql-client-common postgresql-common ssl-cert sysstat Suggested packages: postgresql-doc postgresql-doc-12 libjson-perl openssl-blacklist isag The following NEW packages will be installed: libllvm10 libpq5 postgresql postgresql-12 postgresql-client-12 postgresql-client-common postgresql-common ssl-cert sysstat Ø upgraded, 9 newly installed, to remove and 60 not upgraded. Need to get 30.7 MB of archives. After this operation, 122 MB of additional disk space will be used. Do you want to continue? [Y/n] |
|
1 2 3 |
# vim /etc/postgresql/12/main/postgresql.conf # grep listen_addresses /etc/postgresql/12/main/postgresql.conf listen_addresses = '*' # what IP address(es) to listen on; |
samenet:|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# vim /etc/postgresql/12/main/pg_hba.conf # tail /etc/postgresql/12/main/pg_hba.conf host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 md5 #Hadoop cluster connections host all all samenet md5 # Allow replication connections from localhost, by a user with the # replication privilege. local replication all peer host replication all 127.0.0.1/32 md5 host replication all ::1/128 md5 |
|
1 2 3 |
# sudo su - postgres -c "createuser -s hive -P" Enter password for new role: Enter it again: |
|
1 2 3 4 5 6 7 |
# sudo su - postgres -c "createdb hive" # psql -U hive -h 127.0.0.1 hive Password for user hive: psql (12.17 (Ubuntu 12.17-0ubuntu0.20.04.1)) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. hive=# \q |

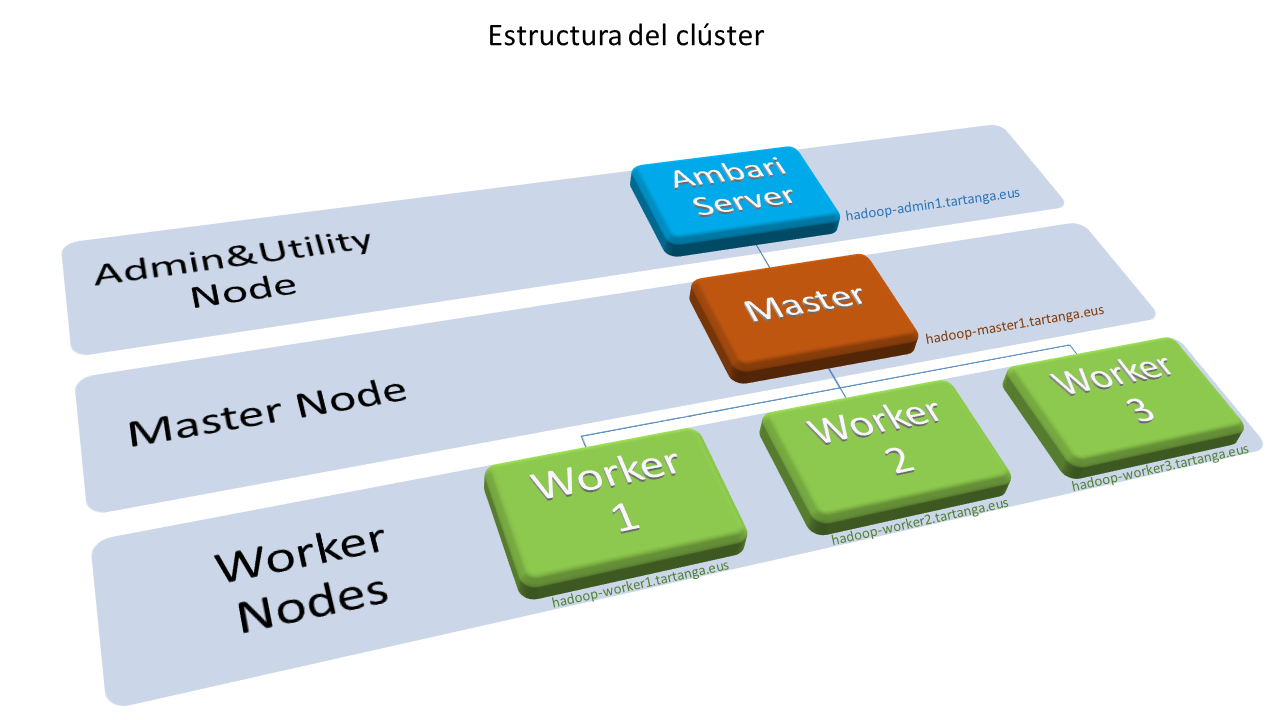
El nodo administrador tendrá la función fundamental de alojar el servidor Ambari que es la herramienta que vamos a utilizar para desplegar y, posteriormente, administrar y monitorizar el clúster. Tendrá menos requisitos de hardware ya que no ejecutará los servicios que forman parte de Hadoop. Lo utilizaremos también como nodo “frontera” para dar servicios adicionales de acceso al clúster.
El servidor elegido para la implementación de este nodo es:

Discos duros 960GB SFF (2,5″)
Los dos discos SSD se configurarán en RAID1 con dos particiones para el directorio raíz y el directorio de arranque:
A continuación puede observarse como han quedado las particiones, sistemas de archivo y su montaje después de la instalación:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 894.3G 0 disk ├─sda1 8:1 0 1.1G 0 part └─sda2 8:2 0 893.2G 0 part └─md1 9:1 0 893.1G 0 raid1 ├─md1p1 259:0 0 1G 0 md /boot └─md1p2 259:1 0 892.1G 0 md / sdb 8:16 0 894.3G 0 disk ├─sdb1 8:17 0 1.1G 0 part /boot/efi └─sdb2 8:18 0 893.2G 0 part └─md1 9:1 0 893.1G 0 raid1 ├─md1p1 259:0 0 1G 0 md /boot └─md1p2 259:1 0 892.1G 0 md / |
La red de datos que conecta los nodos del clúster es una red de alta velocidad en la que cada nodo dispone de dos NIC Ethernet agregadas (“bonded”) mediante LACP. Este enlace agregado proporciona el doble de ancho de banda y tolerancia a fallos, en caso de que uno de los enlaces individuales falle. Cada enlace individual estará conectado a sendos switches CISCO Nexus de la serie 3000 que componen un dominio vPC (virtual PortChannel). En la siguiente figura puede observarse esta estructura, destacada en azul, entre varias configuraciones típicas de conexionado vPC:
Para implementar el Host Port Channel en los servers se han de agregar mediante “bonding” las dos NIC estableciendo los siguientes parámetros:
El archivo de configuración de red queda como sigue:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# cat /etc/netplan/01-bonding-config.yaml network: ethernets: eno1: dhcp4: false eno2: dhcp4: true eno3: dhcp4: true eno4: dhcp4: true eno5: dhcp4: false eno6: dhcp4: false bonds: bond0: interfaces: [eno5, eno6] addresses: [10.22.87.219/24] gateway4: 10.22.87.11 parameters: mode: 802.3ad transmit-hash-policy: layer2 lacp-rate: fast nameservers: addresses: - 10.22.87.1 - 8.8.8.8 search: - TartangaLH.eus version: 2 |
Una vez realizada la personalización de los servicios a desplegar, se revisa un resumen del despliegue a realizar: 
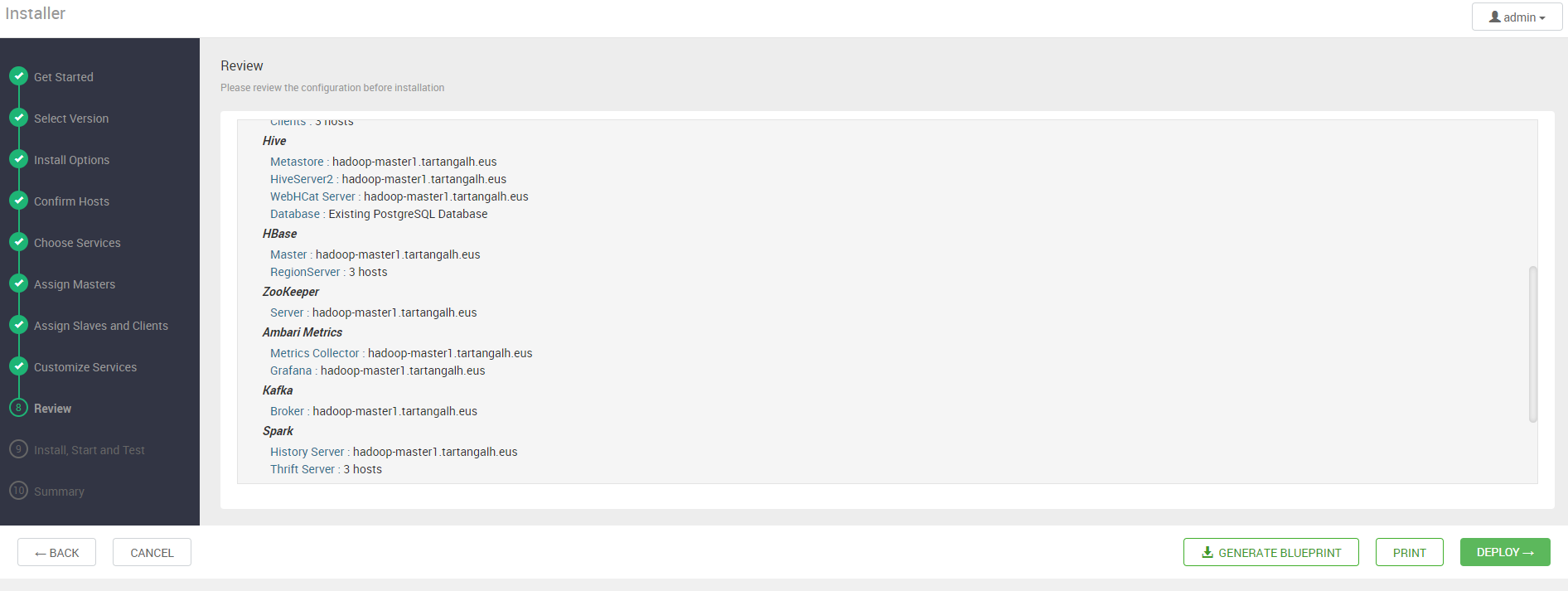

Podemos almacenar esta configuración en forma de “blueprint” pulsando en el botón correspondiente.
Ahora es el momento de desplegar pulsando en el botón “Deploy”. Veremos entonces una interfaz en la que se muestra el progreso del despliegue en cada nodo del clúster:
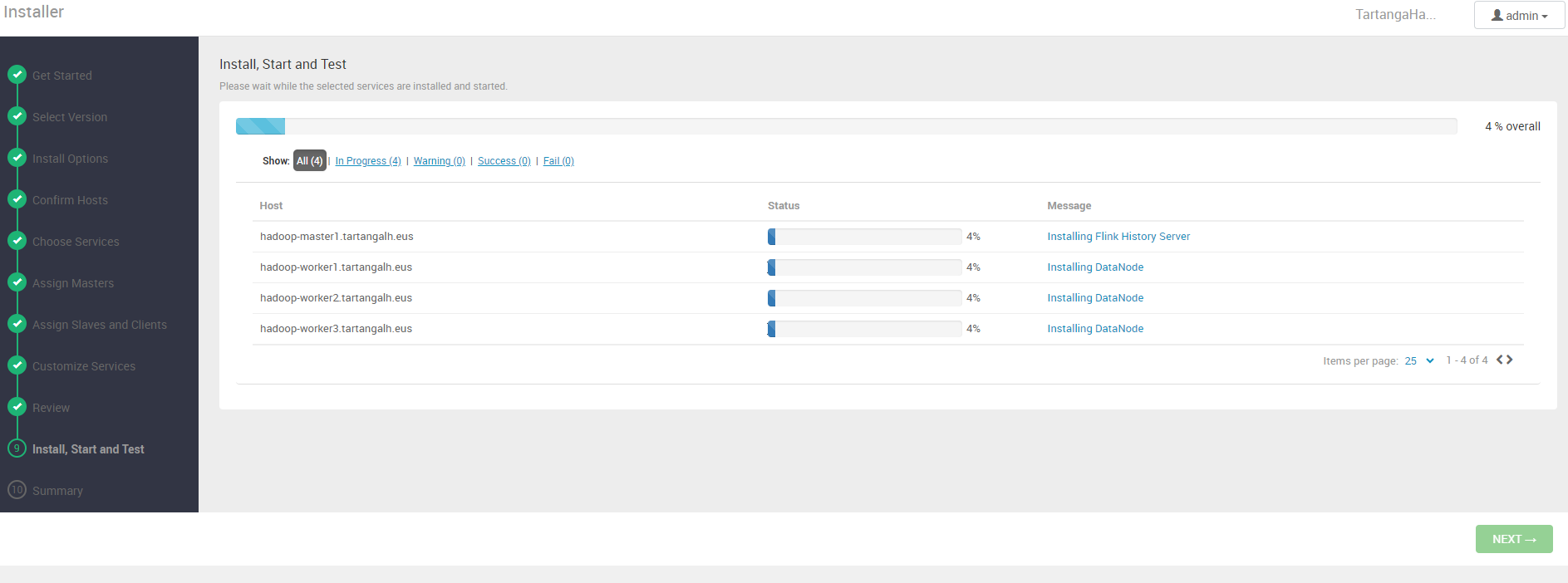
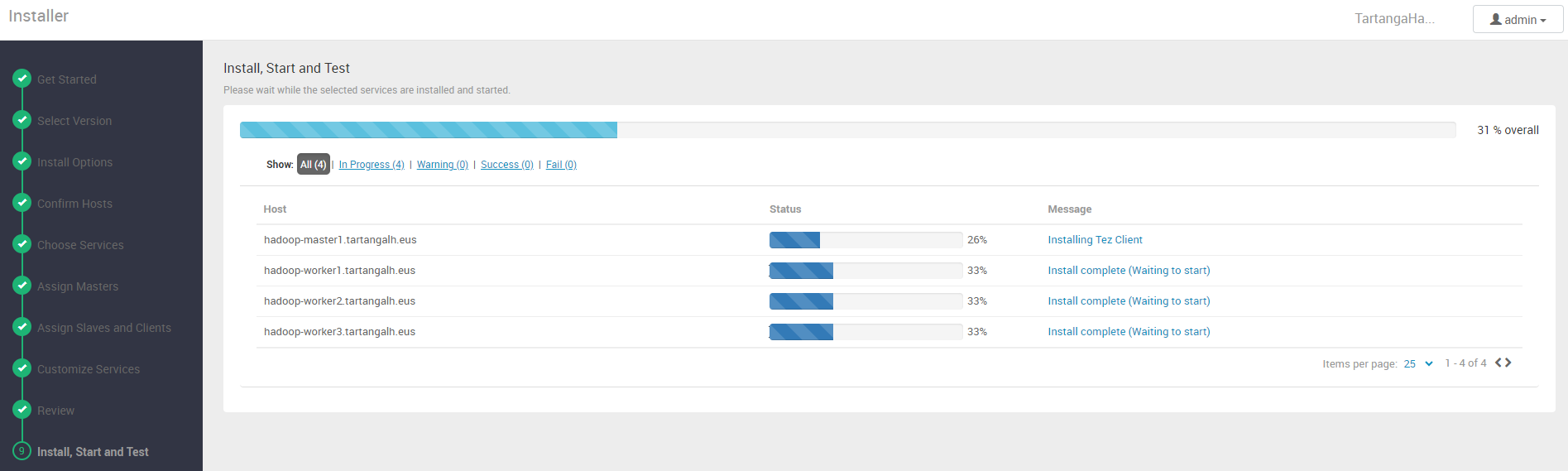
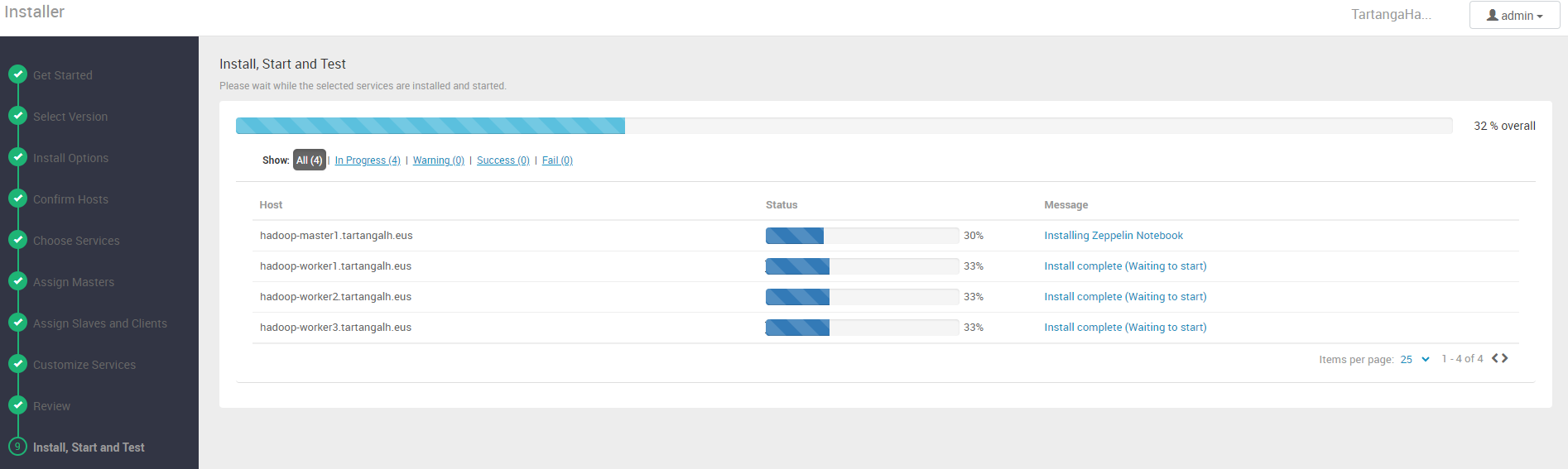
Una vez finalizada la instalación e inicio de servicios, el clúster estará desplegado y al web UI de Ambari nos proporcionará una vista de administración de nuestro clúster, donde podremos monitorizar y re-configurar tanto servicios como nodos:

Podemos observar como habrá servicios no activos que necesiten de nuestra atención y corrección. Estos defectos nos los muestra Ambari mediante un sistema de alertas muy detallado accesible en la UI: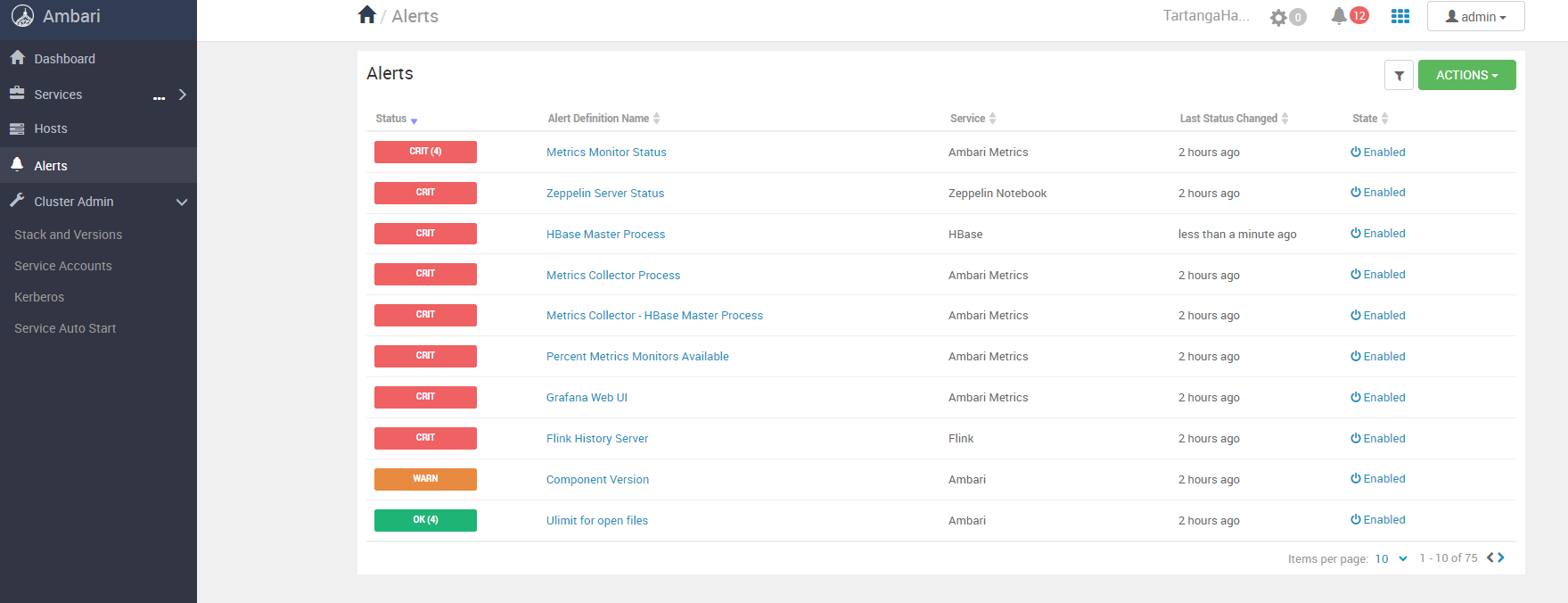
Una vez sean debidamente atendidas estas alertas, podremos visualizar el clúster en un estado estable:

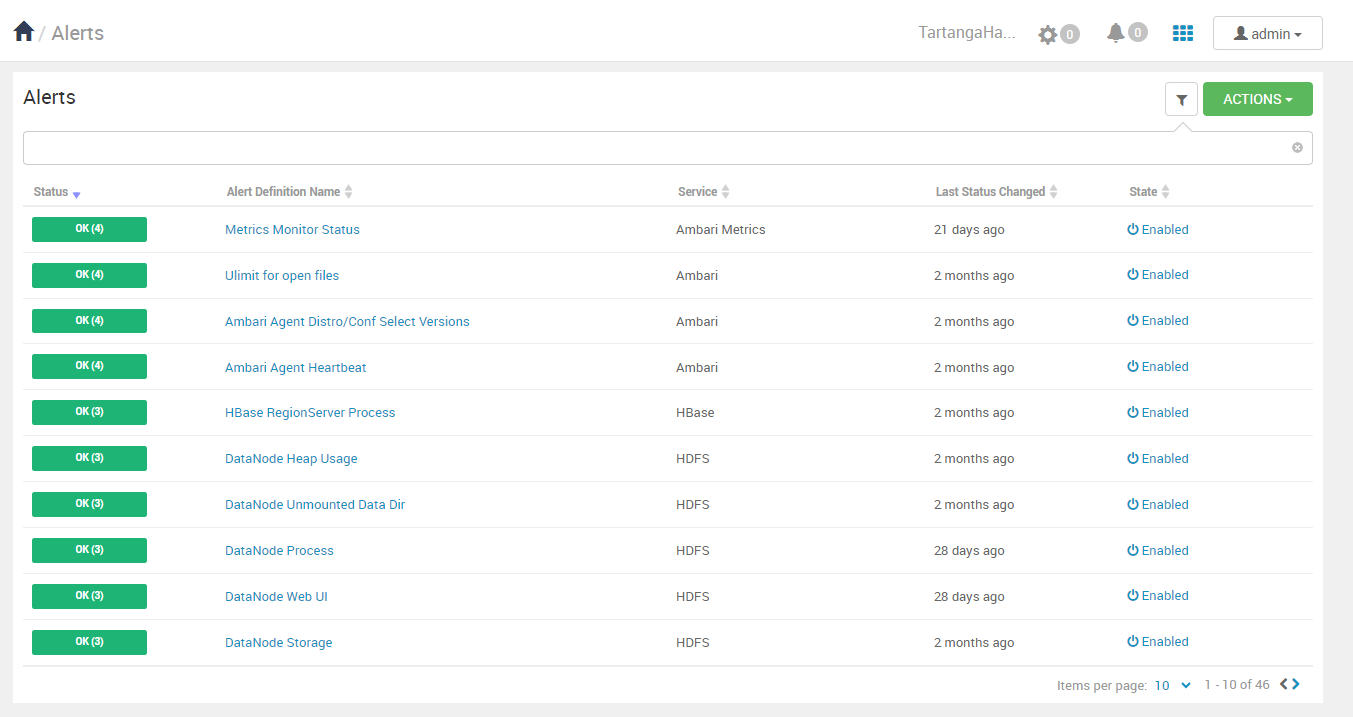
Durante el despliegue, es decir, durante la instalación e inicio de servicios en los nodos, se pueden producir errores que la interfaz nos mostrará de la siguiente forma:

Estos errores se pueden consultar de forma más detallada para su corrección: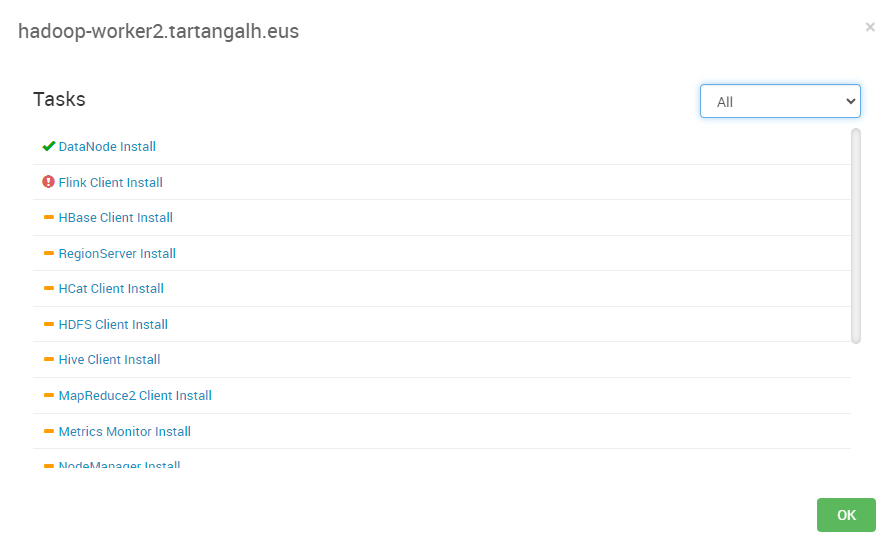
Mediante la interfaz anterior se puede visualizar un log que nos indicará el error en detalle:
stderr:
Traceback (most recent call last):
...
File "/usr/lib/ambari-agent/lib/resource_management/core/sudo.py", line 136, in unlink
os.unlink(path)
OSError: [Errno 21] Is a directory: '/usr/lib/flink/log'
stdout:
...
2024-02-27 07:36:36,670 - Directory['/var/log/flink'] {'mode': 0767}
2024-02-27 07:36:36,670 - Changing permission for /var/log/flink from 755 to 767
2024-02-27 07:36:36,670 - Link['/usr/lib/flink/log'] {'to': '/var/log/flink'}
2024-02-27 07:36:36,671 - Link['/usr/lib/flink/log'] replacing old symlink to /usr/lib/flink/log
Command failed after 1 tries
En este caso se producía un error al intentar reemplazar el enlace simbólico /usr/lib/flink/log ya que era un directorio y no un link. La solución fue borrar dicho directorio y crear el enlace simbólico a /var/log/flink.
Una vez iniciado el servidor ambari podemos entrar a la UI web que es la herramienta que utilizaremos para definir y realizar el despliegue del clúster. Esta aplicación web está disponible en el puerto 8080 del nodo administrador: http://hadoop-admin1.tartangalh.eus:8080/
Una vez dentro, iniciamos un proceso de configuración paso a paso mediante asistente del despliegue a realizar del clúster. A continuación detallamos los diferentes pasos de este asistente.

<?xml version="1.0"?>
<repository-version xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="version_definition.xsd">
<release>
<type> STANDARD </type>
<stack-id> BGTP-1.0 </stack-id>
<version> 1.0 </version>
<build> 1 </build>
<release-notes> https://bigtop.apache.org/release-notes.html </release-notes>
<display> BGTP-3.1.1 </display>
</release>
<manifest>
<service id="AMBARI-METRICS" name="AMBARI-METRICS" version="Bigtop+3.2"/>
<service id="FLINK-321" name="FLINK" version="Bigtop+3.2"/>
<service id="HBASE-321" name="HBASE" version="Bigtop+3.2"/>
<service id="HDFS-321" name="HDFS" version="Bigtop+3.2"/>
<service id="HIVE-321" name="HIVE" version="Bigtop+3.2"/>
<service id="KAFKA-321" name="KAFKA" version="Bigtop+3.2"/>
<service id="SOLR-321" name="SOLR" version="Bigtop+3.2"/>
<service id="SPARK-321" name="SPARK" version="Bigtop+3.2"/>
<service id="TEZ-321" name="TEZ" version="Bigtop+3.2"/>
<service id="YARN-321" name="YARN" version="Bigtop+3.2"/>
<service id="ZEPPELIN-321" name="ZEPPELIN" version="Bigtop+3.2"/>
<service id="ZOOKEEPER-321" name="ZOOKEEPER" version="Bigtop+3.2"/>
</manifest>
<available-services/>
<repository-info>
<os family="ubuntu18">
<repo>
<baseurl> http://repos.bigtop.apache.org/releases/3.1.1/ubuntu/18.04/$(ARCH) </baseurl>
<repoid> BGTP-3.1.1 </repoid>
<reponame> BGTP </reponame>
</repo>
</os>
</repository-info>
</repository-version>


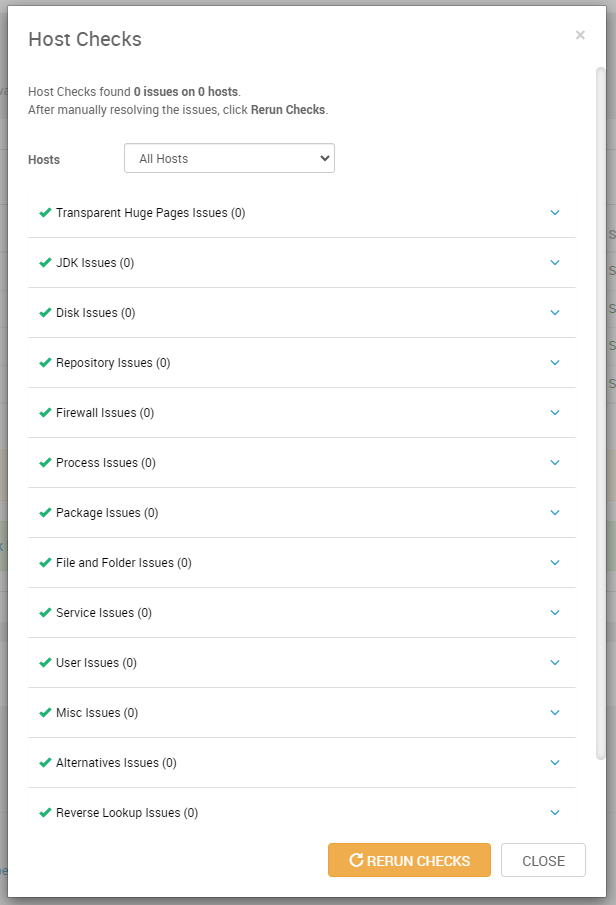

hadoop-master1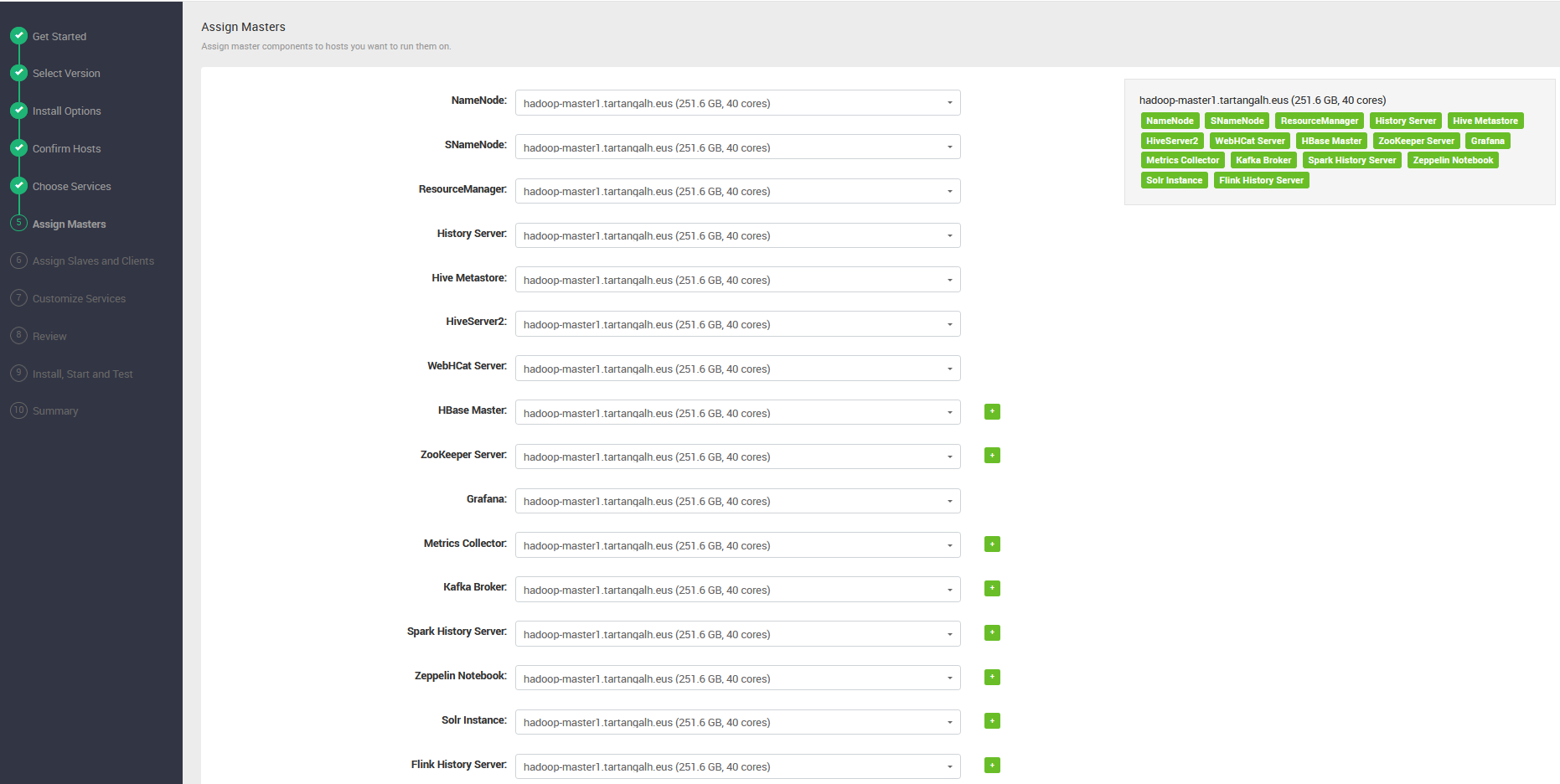
hadoop-worker1, hadoop-worker2 y hadoop-worker3









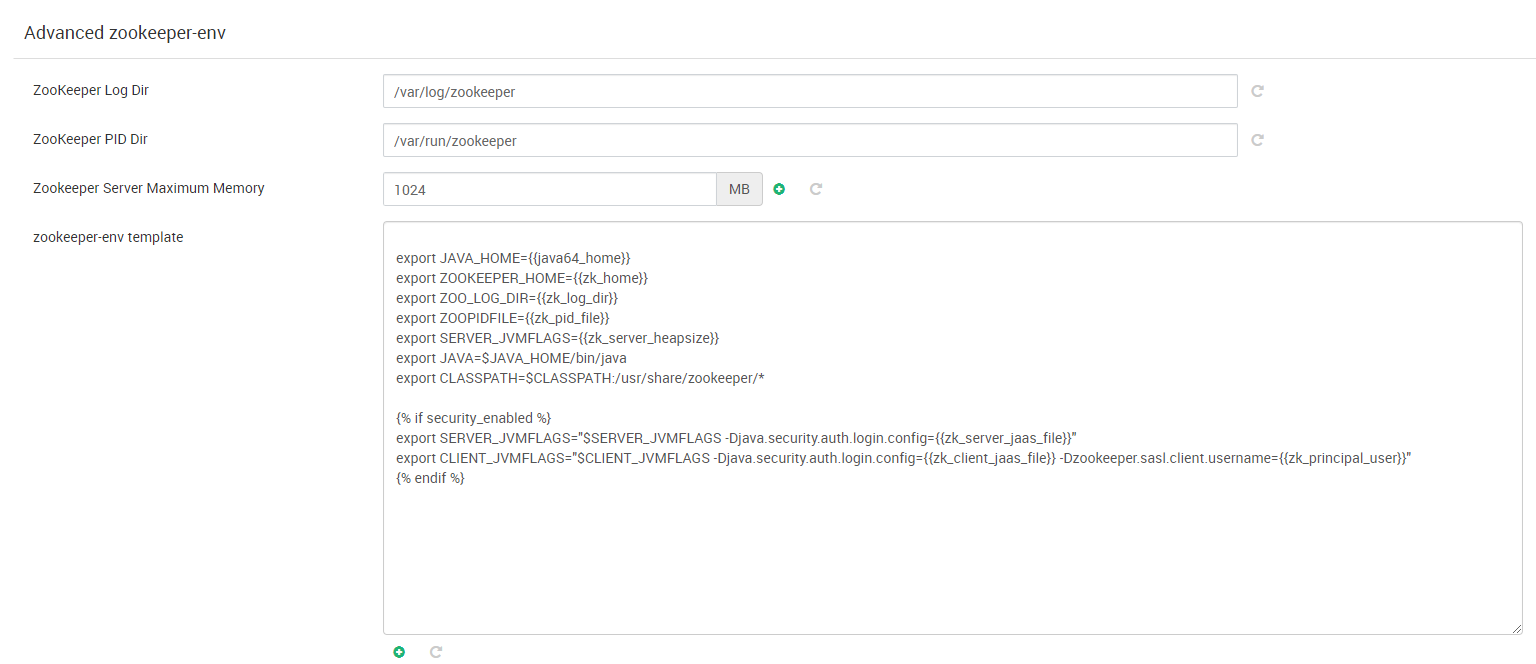
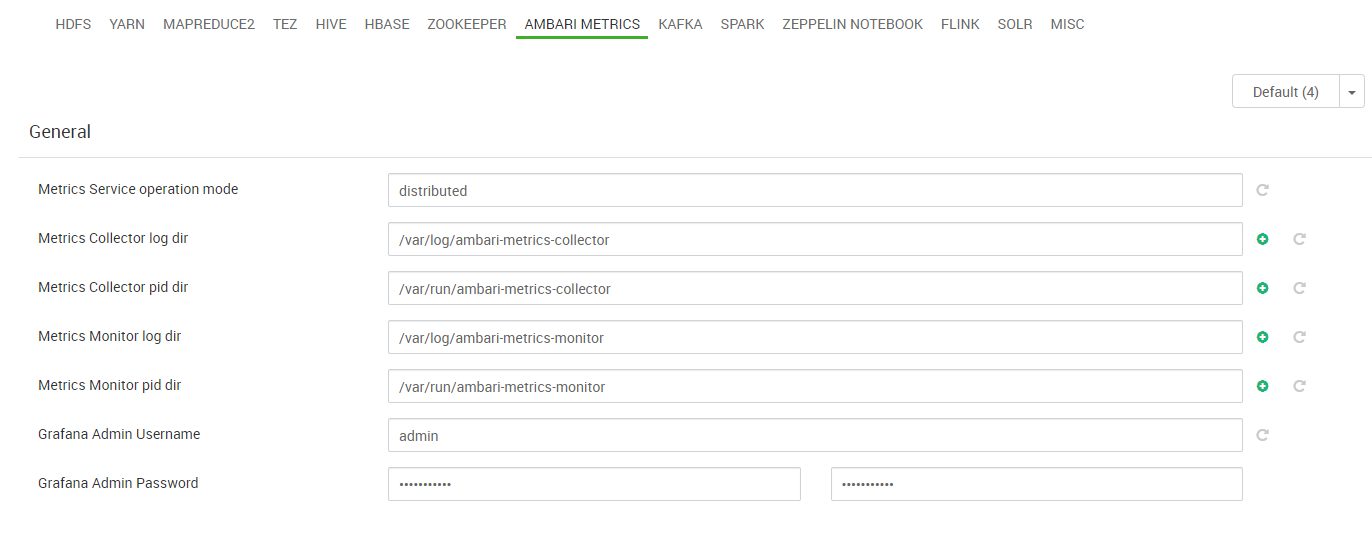

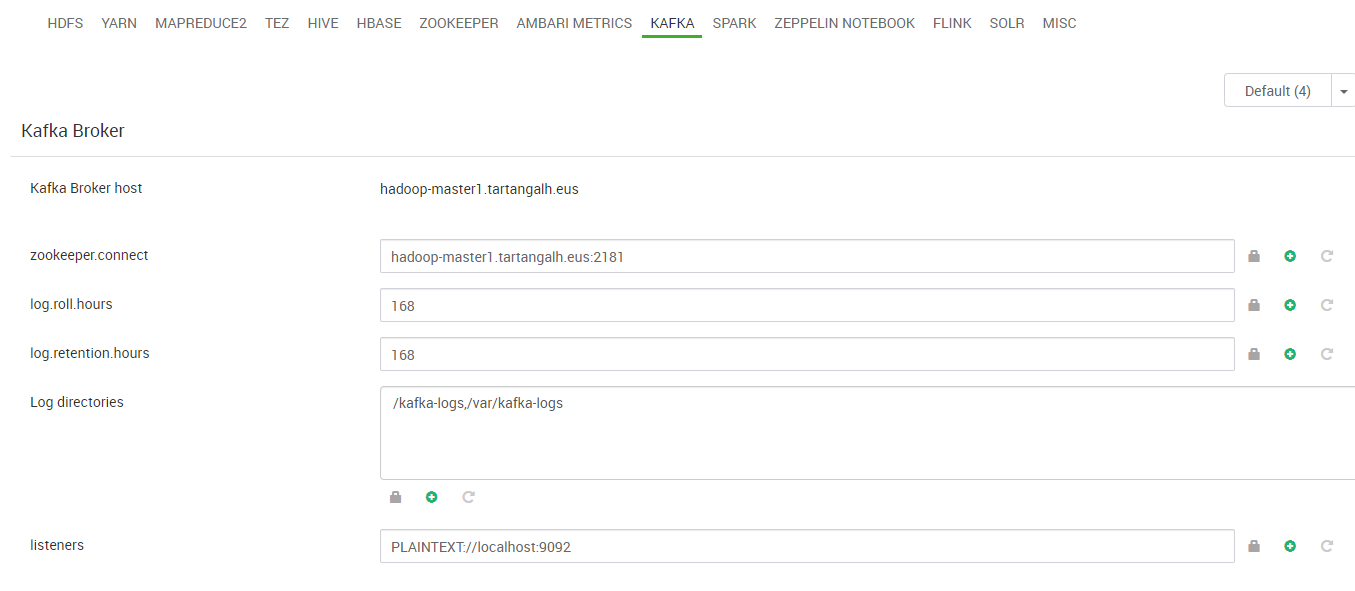

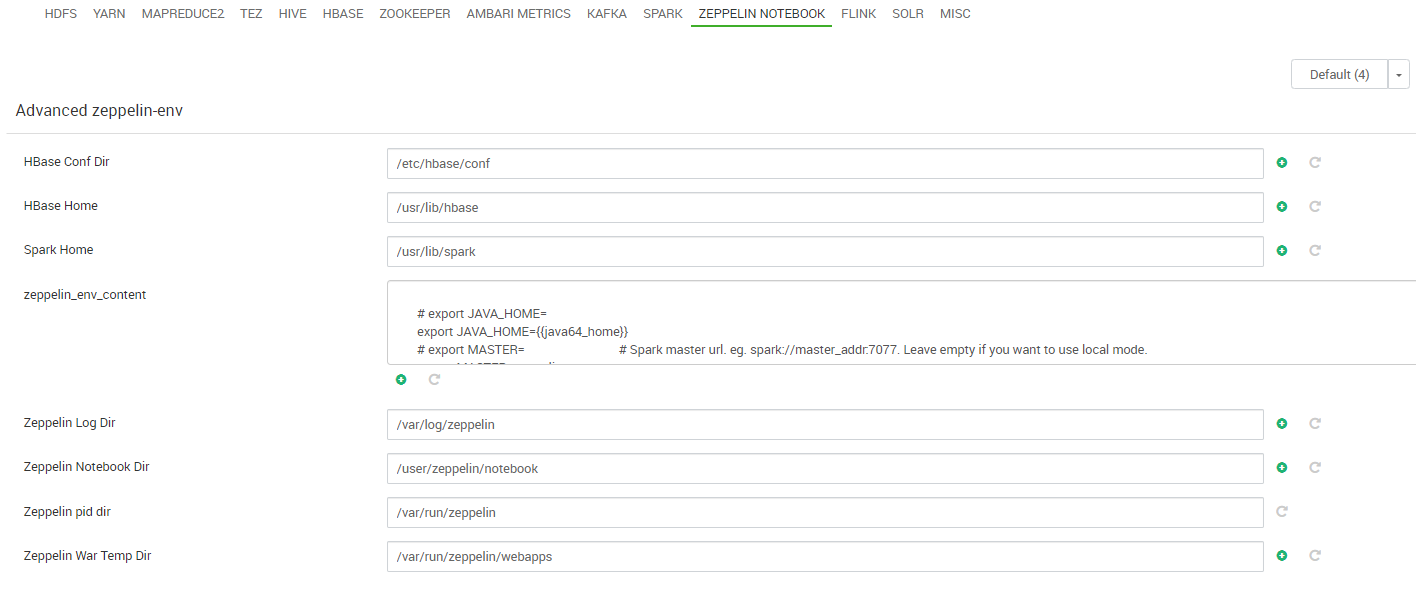


Durante el despliegue del clúster, los nodos deben acceder a algún repositorio de software del que obtener los paquetes que se van a instalar para cada servicio que va a ejecutar. Este repositorio contiene los paquetes que forman parte del “stack” de aplicaciones/servicios Hadoop elegidos para el clúster. Existen diversos stacks de Hadoop pero la mayoría de ellos son propietarios y pocos accesibles en repositorios públicos. El stack de Hadoop elegido para nuestro clúster es BigTop, concretamente la versión 3.1.1.
Para configurar dicho repositorio se realizan los siguientes pasos:
|
1 |
# wget --no-check-certificate -O- https://archive.apache.org/dist/bigtop/bigtop-3.1.1/repos/GPG-KEY-bigtop | apt-key add - |
|
1 2 |
# cat /etc/apt/sources.list.d/ambari.list deb http://repos.bigtop.apache.org/releases/3.1.1/ubuntu/18.04/$(ARCH) bigtop contrib |