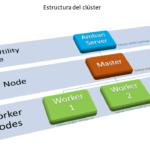
El nodo administrador tendrá, entre otras, la función de ejecutar un servidor Ambari para el despliegue y posterior gestión del clúster. Por lo tanto hemos de instalar y configurar dicho servidor Ambari. La instalación se realiza de la siguiente forma:
|
|
# apt update # apt install ambari-server |
Nótese que al realizar esta instalación se ha instalado un servidor postgresql.
Una vez realizada la instalación realizaremos la configuración del servidor con el comando ambari-server setup:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# ambari-server setup Using python /usr/bin/python Setup ambari-server Checking SELinux... WARNING: Could not run /usr/sbin/sestatus: OK Customize user account for ambari-server daemon [y/n] (n)? n Adjusting ambari-server permissions and ownership... Checking firewall status... Checking JDK... Do you want to change Oracle JDK [y/n] (n)? n Check JDK version for Ambari Server... JDK version found: 8 Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server. Checking GPL software agreement... Completing setup... Configuring database... Enter advanced database configuration [y/n] (n)? n Configuring database... Default properties detected. Using built-in database. Configuring ambari database... Checking PostgreSQL... Configuring local database... Configuring PostgreSQL... Backup for pg_hba found, reconfiguration not required Creating schema and user... done. Creating tables... done. Extracting system views... Adjusting ambari-server permissions and ownership... Ambari Server 'setup' completed successfully. |
Nótese las respuestas dadas a las diferentes preguntas del proceso de configuración.
Finalmente, para instalar el stack BigTop 3.1.1 y que esté disponible al desplegar el clúster, hemos de instalar el “management pack” de BigTop:
|
|
# apt install bigtop-ambari-mpack bigtop-utils # service ambari-server stop # env -u _JAVA_HOME ambari-server install-mpack --mpack=/usr/lib/bigtop-ambari-mpack/bgtp-ambari-mpack-1.0.0.0-SNAPSHOT-bgtp-ambari-mpack.tar.gz --verbose # service ambari-server start |



