El clúster que se pretende desplegar es un clúster Hadoop mínimo que permite almacenar y procesar, a “bajo” coste, grandes volúmenes de datos. Estos clústeres están constituidos por un conjunto de servicios y aplicaciones que forman el llamado ecosistema Hadoop:

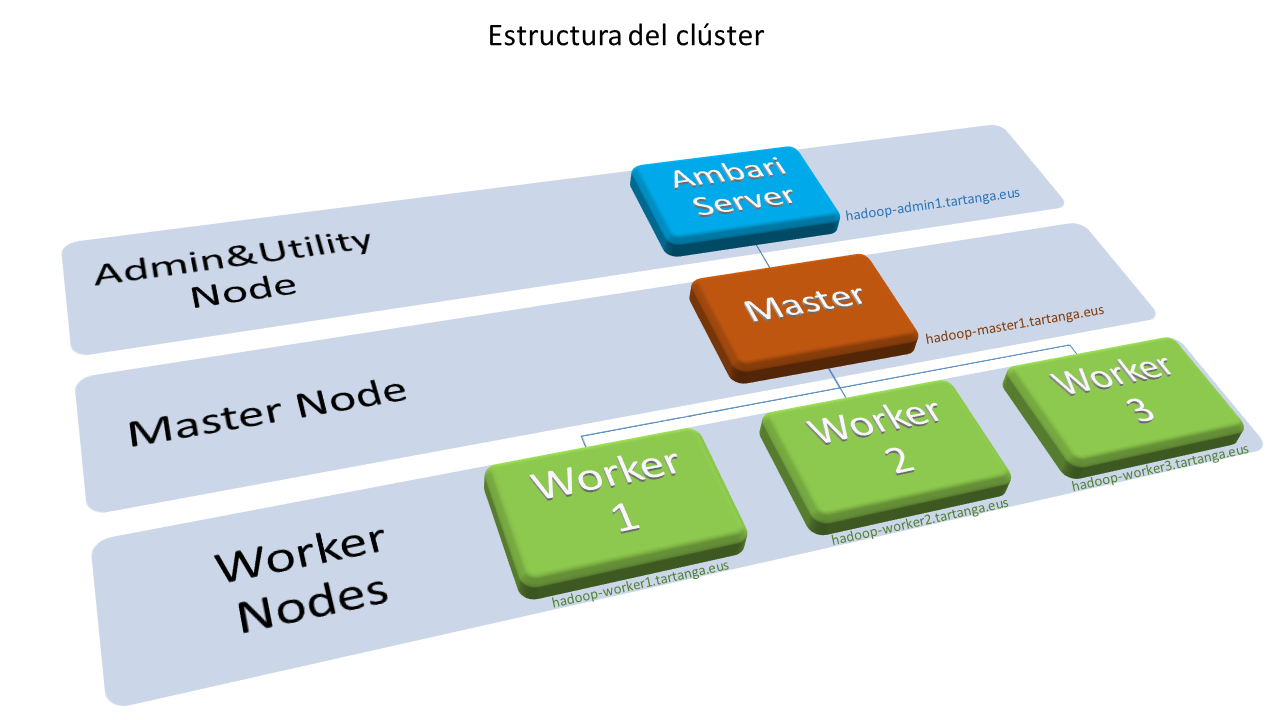
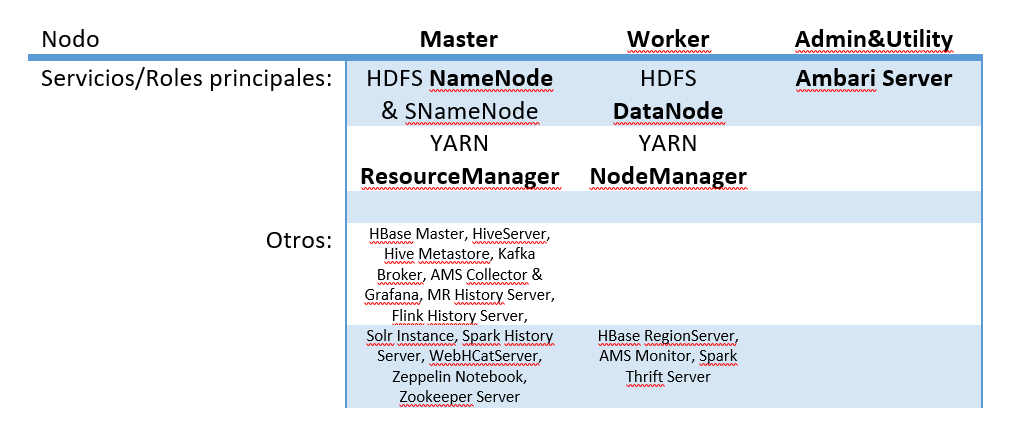
El clúster está compuesto por diferentes nodos que ejecutan un conjunto de los servicios de Hadoop, podemos decir que ejercen un rol, dentro del clúster. En la siguiente tabla se listan los servicios/roles de los diferentes nodos del clúster:
La siguiente figura muestra un diagrama de la estructura funcional y pseudo-física del clúster: